Collecting and Parsing FBI National DNA Index System Statistics from Wayback Machine
Author
Tina Lasisi | João P. Donadio
Published
November 9, 2025
Introduction
The National DNA Index System (NDIS) is the central database that allows accredited forensic laboratories across the United States to electronically exchange and compare DNA profiles. Maintained by the FBI as part of CODIS (Combined DNA Index System), NDIS tracks the accumulation of DNA records contributed by federal, state, and local laboratories.
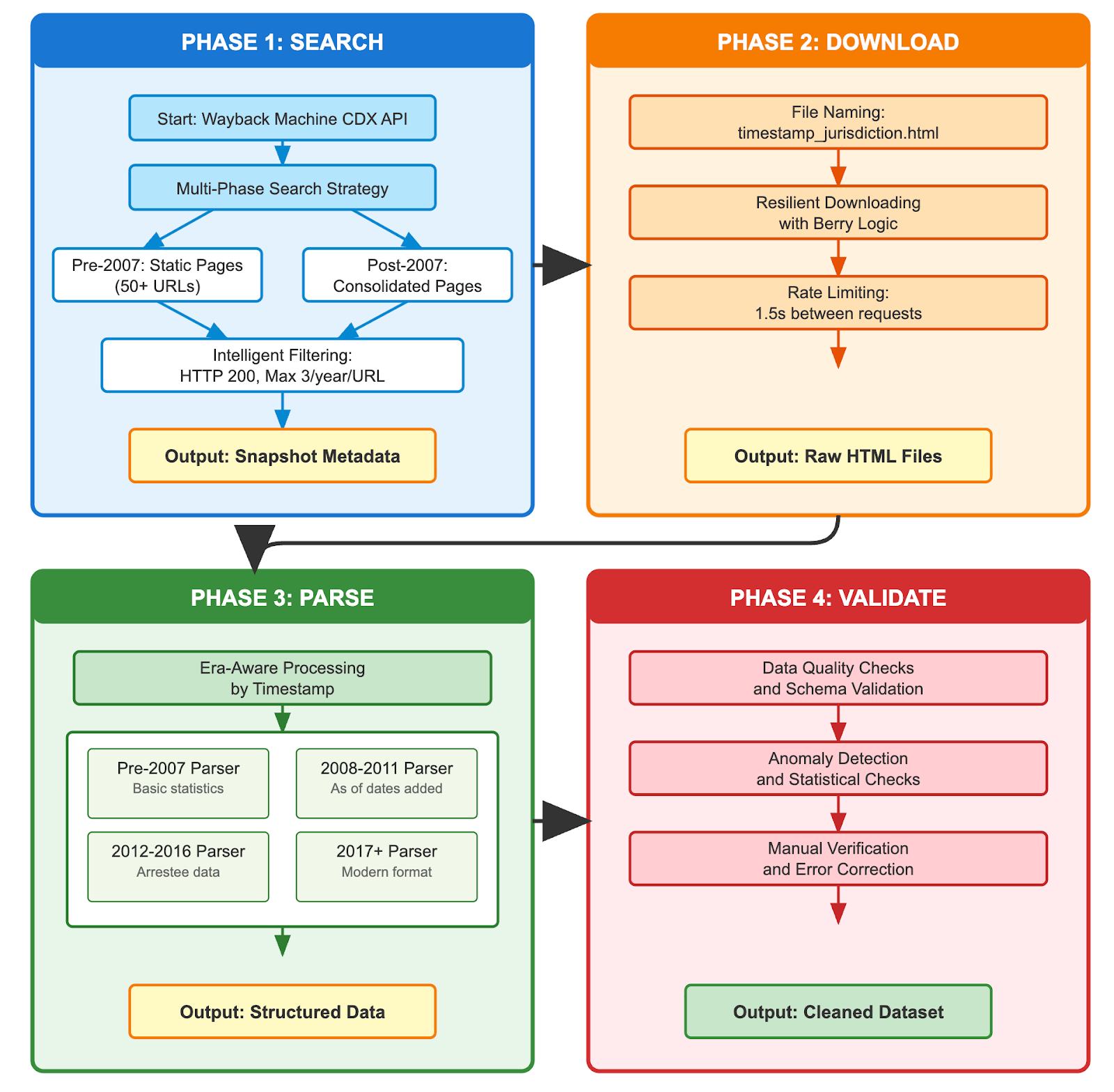
This project focuses on systematically compiling the growth and evolution of NDIS by parsing historical statistics published on the FBI’s website and preserved in the Internet Archive’s Wayback Machine. These snapshots contain tables reporting the number of DNA profiles stored in NDIS (offender, arrestee, forensic), as well as information on laboratory participation across jurisdictions.
Objectives
Develop a reproducible pipeline to extract NDIS statistics from archived FBI webpages in the Wayback Machine.
Identify and correct inconsistencies and data quality issues across historical snapshots.
Document the expansion of DNA profiles (offender, arrestee, forensic) over time.
Methodology
Project step-by-step
Setup and Configuration
System Requirements
Required Packages:
Core: requests, beautifulsoup4, and lxml (scraping/parsing).
Data/Visualization: pandas and tqdm (progress tracking).
Show Configuration code
import sysimport subprocessimport importlibrequired_packages = ['requests', # API/HTTP'beautifulsoup4', # HTML parsing'lxml', # Faster parsing'pandas', # Data handling'tqdm', # Progress bars'hashlib','collections','pathlib','datetime','os']for package in required_packages:try: importlib.import_module(package)print(f"✓ {package} already installed")exceptImportError:print(f"Installing {package}...") subprocess.check_call([sys.executable, "-m", "pip", "install", package])print(f"📚 All required packages are installed.")
Project Structure
Main Configurations:
Directory paths for raw HTML (data_snapshots), metadata (data_metadata), and outputs (data_outputs).
Standardization mappings for jurisdiction names and known data typos.
Show Configuration code
from pathlib import Pathimport re, json, requests, time, hashlibfrom datetime import datetimeimport pandas as pdfrom bs4 import BeautifulSoupfrom tqdm.auto import tqdmfrom datetime import datetimefrom collections import defaultdictimport os# ConfigurationBASE_DIR = Path("..") # Project root directoryHTML_DIR = BASE_DIR /"data"/"ndis"/"raw"/"ndis_snapshots"# Storage for downloaded HTMLMETA_DIR = BASE_DIR /"data"/"ndis"/"raw"/"ndis_metadata"# Metadata storageOUTPUT_DIR = BASE_DIR /"data"/"ndis"/"raw"# Processed data outputNDIS_SNAPSHOTS_DIR = HTML_DIRNDIS_SNAPSHOTS_DIR.mkdir(parents=True, exist_ok=True)# Create directory structurefor directory in [HTML_DIR, META_DIR, OUTPUT_DIR]: directory.mkdir(parents=True, exist_ok=True)
Project directories initialized:
- Working directory: /Users/tlasisi/GitHub/PODFRIDGE-Databases
- HTML storage: ../data/ndis/raw/ndis_snapshots
- Metadata directory: ../data/ndis/raw/ndis_metadata
- Output directory: ../data/ndis/raw
Wayback Machine Snapshot Search
A function was developed to systematically search the Internet Archive’s Wayback Machine for all preserved snapshots of FBI NDIS statistics pages using a comprehensive multi-phase approach.
Scraping Method
Multi-Phase Search Strategy:
First searches for snapshots from the pre-2007 era using state-specific URLs
Then targets consolidated pages from post-2007 periods
Failed requests are tracked and retried with increased retry attempts
Preserves complete error context for troubleshooting
Technical Implementation
API Request
Converts JSON responses to clean DataFrame
Sorts chronologically (oldest → newest)
Core Search Implementation
make_request_with_retry(): Implements exponential backoff (1s → 2s → 4s delays) for fault-tolerant API requests with configurable retry attempts.
Show search helpers function code
def make_request_with_retry(params, max_retries=3, initial_delay=1): API_URL ="https://web.archive.org/cdx/search/cdx" delay = initial_delayfor attempt inrange(max_retries):try: resp = requests.get(API_URL, params=params, timeout=30) resp.raise_for_status()print(f"✓ Successful request for {params['url']} (offset: {params.get('offset', 0)})")return respexcept requests.exceptions.RequestException as e:if attempt == max_retries -1:print(f"✗ Final attempt failed for {params['url']} (offset: {params.get('offset', 0)}): {str(e)}")returnNoneprint(f"! Attempt {attempt+1} failed for {params['url']}, retrying in {delay} seconds...") time.sleep(delay) delay *=2
Evolution of the NDIS Webpage (2001–2025)
Over the years, the NDIS statistics webpage has evolved considerably in both structure and design. Early versions (2001–2007) displayed state-level statistics through individual HTML pages (e.g., ne.htm for Nebraska), accessible via a clickable U.S. map interface. From 2008 onward, the FBI consolidated all states and agencies into unified pages, simplifying data retrieval and standardizing presentation formats. This evolution reflects ongoing modernization of the FBI’s online data systems, transitioning from fragmented, state-specific sources to more cohesive and accessible datasets.
Website Formats
Pre-2007 (Clickmap Era)
Each state/agency has its own page (e.g., ne.htm for Nebraska, dc.htm for DC/FBI Lab).
The search iterates through the known two-letter codes and queries Wayback for each URL individually.
search_pre2007_snapshots(): Searches individual state-specific pages using 50+ state codes (al.htm, ak.htm, etc.).
Show pre-2007 search function code
def search_pre2007_snapshots(): state_codes = ["al", "ak", "az", "ar", "ca", "co", "ct", "de", "dc","fl", "ga", "hi", "id", "il", "in", "ia", "ks", "ky","la", "me", "md", "ma", "mi", "mn", "ms", "mo", "mt","ne", "nv", "nh", "nj", "nm", "ny", "nc", "nd", "oh","ok", "or", "pa", "pr", "ri", "sc", "sd", "tn", "tx","army", "ut", "vt", "va", "wa", "wv", "wi", "wy"] all_rows = [] seen_timestamps =set() total_saved =0print(f"Starting pre-2007 snapshot search for {len(state_codes)} state codes at {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")for i, code inenumerate(state_codes, 1): url =f"http://www.fbi.gov/hq/lab/codis/{code}.htm" offset =0 state_snapshots =0 has_more_results =Trueprint(f"\n[{i}/{len(state_codes)}] Searching for {code.upper()} snapshots...")while has_more_results: params = {"url": url,"matchType": "exact","output": "json","fl": "timestamp,original,mimetype,statuscode","filter": ["statuscode:200", "mimetype:text/html"],"limit": "5000","offset": str(offset) } resp = make_request_with_retry(params, max_retries=5, initial_delay=2)ifnot resp: print(f"✗ Failed to retrieve {code.upper()}")break data = resp.json()iflen(data) <=1:print(f" No more results for {code.upper()} at offset {offset}") has_more_results =Falsebreak new_snapshots =0for row in data[1:]: timestamp = row[0]if timestamp notin seen_timestamps: all_rows.append(row) seen_timestamps.add(timestamp) new_snapshots +=1 state_snapshots +=1 total_saved +=1if new_snapshots >0:print(f" → Saved {new_snapshots} new snapshots for {code.upper()} (offset: {offset})")# Check if we've reached the end of resultsiflen(data) <5001:print(f" Reached end of results for {code.upper()} at offset {offset}") has_more_results =Falseelse: offset +=5000 time.sleep(1) # Brief pause between requestsif state_snapshots >0:print(f"✓ Found {state_snapshots} total snapshots for {code.upper()}")else:print(f"✗ No snapshots found for {code.upper()}")print(f"\nPre-2007 search completed. Total snapshots saved: {total_saved}")return pd.DataFrame(all_rows, columns=["timestamp","original","mimetype","status"]), 0
Post-2007 (Consolidated Pages)
All state/agency records are on a single page per snapshot.
Searches use the known consolidated URL patterns per era.
search_post2007_snapshots(): Searches consolidated pages across 5 historical URL patterns with both HTTP and HTTPS variants.
Show search function code
def search_post2007_snapshots(): urls = ["https://www.fbi.gov/hq/lab/codis/stats.htm","https://www.fbi.gov/about-us/lab/codis/ndis-statistics","https://www.fbi.gov/about-us/lab/biometric-analysis/codis/ndis-statistics","https://www.fbi.gov/services/laboratory/biometric-analysis/codis/ndis-statistics","https://le.fbi.gov/science-and-lab/biometrics-and-fingerprints/codis/codis-ndis-statistics" ] all_rows = [] seen_timestamps =set() protocols = ["http://", "https://"] total_saved =0print(f"Starting post-2007 snapshot search for {len(urls)} URLs at {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")for i, base_url inenumerate(urls, 1): url_snapshots =0for protocol in protocols: current_url = base_url.replace("https://","").replace("http://","") full_url =f"{protocol}{current_url}" offset =0 has_more_results =Trueprint(f"\n[{i}/{len(urls)}] Searching for {full_url} snapshots...")while has_more_results: params = {"url": full_url,"matchType": "exact","output": "json","fl": "timestamp,original,mimetype,statuscode","filter": ["statuscode:200", "mimetype:text/html"],"limit": "5000","offset": str(offset) } resp = make_request_with_retry(params, max_retries=5, initial_delay=2)ifnot resp: print(f"✗ Failed to retrieve {full_url}")break data = resp.json()iflen(data) <=1:print(f" No more results for {full_url} at offset {offset}") has_more_results =Falsebreak new_snapshots =0for row in data[1:]: timestamp = row[0]if timestamp notin seen_timestamps: all_rows.append(row) seen_timestamps.add(timestamp) new_snapshots +=1 url_snapshots +=1 total_saved +=1if new_snapshots >0:print(f" → Saved {new_snapshots} new snapshots for {full_url} (offset: {offset})")iflen(data) <5001:print(f" Reached end of results for {full_url} at offset {offset}") has_more_results =Falseelse: offset +=5000 time.sleep(1)if url_snapshots >0:print(f"✓ Found {url_snapshots} total snapshots for {base_url}")else:print(f"✗ No snapshots found for {base_url}")print(f"\nPost-2007 search completed. Total snapshots saved: {total_saved}")return pd.DataFrame(all_rows, columns=["timestamp","original","mimetype","status"]), 0
Search Execution
Calls both pre-2007 and post-2007 search functions to retrieve comprehensive NDIS records.
Combines results and removes duplicates based on timestamps.
This system provides a robust method for downloading historical webpage snapshots from the Internet Archive’s Wayback Machine, specifically designed for the FBI NDIS statistics pages.
Download Methods
The download system implements a sequential approach optimized for reliability and respectful API usage:
Resilient Downloading: Automatic retries with exponential backoff (2s → 4s → 8s → 16s → 32s delays) and extended 60-second timeouts for reliable network handling
Smart File Management: Context-aware naming scheme using timestamp + state/scope identifier (e.g., 20040312_ne.html for pre-2007, 20150621_ndis.html for post-2007)
Progress Tracking: Real-time download status with completion counters and detailed success/failure reporting
Rate Limiting: 1.5-second delays between requests to avoid overloading the Wayback Machine servers
Show downloader helpers code
def download_with_retry(url, save_path, max_retries=4, initial_delay=2):""" Download an archived snapshot with retries and exponential backoff. """ delay = initial_delayfor attempt inrange(max_retries):try: resp = requests.get(url, timeout=120) resp.raise_for_status()# Validate content is reasonableiflen(resp.content) <500:ifb"error"in resp.content.lower() orb"not found"in resp.content.lower():raise requests.exceptions.RequestException(f"Possible error page: {len(resp.content)} bytes")# Save to diskwithopen(save_path, "wb") as f: f.write(resp.content)print(f"✓ Downloaded: {save_path}")returnTrueexcept requests.exceptions.RequestException as e:if attempt == max_retries -1:print(f"✗ Final attempt failed for {url}: {str(e)}")returnFalseprint(f"! Attempt {attempt+1} failed, retrying in {delay}s...") time.sleep(delay) delay *=2returnFalsedef snapshot_to_filepath(row):""" Map a snapshot record to a local filename. Format: {timestamp}_{state_or_scope}.html """ ts = row["timestamp"] original = row["original"]# derive name from FBI URL patternif"/codis/"in original and original.endswith(".htm"):# Pre-2007: use last part (state code or army/dc) suffix = Path(original).stemelse:# Post-2007: consolidated page, use 'ndis' suffix ="ndis" save_dir = HTML_DIR save_dir.mkdir(parents=True, exist_ok=True) # Ensure directory existsreturn save_dir /f"{ts}_{suffix}.html"
Download Execution
The download execution phase performs bulk retrieval of historical NDIS snapshots with comprehensive error handling:
Sequential Processing: Iterates through snapshot DataFrame chronologically, processing each file individually for maximum reliability
URL Construction: Uses identity flag (id_) in archive URLs to retrieve unmodified original content: https://web.archive.org/web/{timestamp}id_/{original}
Binary Preservation: Saves files as binary content to maintain original encoding and prevent character corruption
Comprehensive Logging: Provides real-time progress updates with attempt counters and final success/failure statistics
Flexible Limiting: Optional download limits for testing or partial processing
Show download execution code
def download_snapshots(snap_df, limit=None):""" Iterate over snapshot DataFrame and download archived HTML pages. """ total =len(snap_df) if limit isNoneelsemin(limit, len(snap_df))print(f"Starting download of {total} snapshots at {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}") successes, failures =0, 0 failed_downloads = []for i, row inenumerate(snap_df.head(total).itertuples(index=False), 1): ts, original, _, _ = row save_path = snapshot_to_filepath(row._asdict())if save_path.exists() and save_path.stat().st_size >1000:print(f"- [{i}/{total}] Already exists: {save_path}") successes +=1continue archive_url =f"https://web.archive.org/web/{ts}id_/{original}"print(f"- [{i}/{total}] Downloading {archive_url}")if download_with_retry(archive_url, save_path): successes +=1else: failures +=1 failed_downloads.append({'timestamp': ts,'url': original,'archive_url': archive_url })if i %50==0:print(f"Progress: {i}/{total} ({i/total*100:.1f}%) - {successes} success, {failures} failures") time.sleep(1.5)# Save failure reportif failed_downloads: failure_report = {'download_completed': datetime.now().isoformat(),'total_attempted': total,'successful': successes,'failed': failures,'failed_downloads': failed_downloads }withopen(META_DIR /"download_failures.json", 'w') as f: json.dump(failure_report, f, indent=2)print(f"\nDownload completed. Success: {successes}, Failures: {failures}")return successes, failuressuccesses, failures = download_snapshots(snap_df, limit=None)
Download Validation
Post-download validation ensures data integrity and identifies potential issues:
File Existence Verification: Checks that all expected files were successfully downloaded to the target directory
Content Quality Assessment: Validates HTML content by examining file headers for proper HTML tags
Error Categorization: Separates missing files from corrupted/non-HTML files for targeted remediation
Metadata Generation: Creates JSON validation reports with detailed statistics and file counts
Actionable Reporting: Provides clear feedback on download success rates and files requiring attention
Show download validation code
def validate_downloads(snap_df):""" Validate downloaded files exist and are HTML-like. """ missing, bad_html = [], []for row in snap_df.itertuples(index=False): save_path = snapshot_to_filepath(row._asdict())ifnot save_path.exists(): missing.append(save_path)continuetry: file_size = save_path.stat().st_sizeif file_size <1000: bad_html.append(save_path)continuewithopen(save_path, "rb") as f: start = f.read(500).lower()ifb"<html"notin start andb"<!doctype"notin start: bad_html.append(save_path)exceptException: bad_html.append(save_path)print(f"Validation results → Missing: {len(missing)}, Bad HTML: {len(bad_html)}")return missing, bad_html# Run validationmissing, bad_html = validate_downloads(snap_df)# Save validation summaryvalidation_meta = {"validation_performed": datetime.now().isoformat(),"missing_files": len(missing),"bad_html_files": len(bad_html),"total_snapshots": len(snap_df),"successful_downloads": successes,"success_rate": f"{(successes/len(snap_df))*100:.1f}%"}withopen(META_DIR /"validation_metadata.json", "w") as f: json.dump(validation_meta, f, indent=2)
Show validation report code
# Save and print reportreport_path = META_DIR /f"validation_metadata.json"withopen(report_path, 'w') as f: json.dump(validation_meta, f, indent=2)print(f"\n{'='*60}")print("DOWNLOAD VALIDATION REPORT")print(f"{'='*60}")print(f" Missing files: {validation_meta['missing_files']}/{validation_meta['total_snapshots']}")print(f" Bad HTML files: {validation_meta['bad_html_files']}/{validation_meta['total_snapshots']}")print(f" Successful downloads: {validation_meta['successful_downloads']}/{validation_meta['total_snapshots']} ({validation_meta['success_rate']})")print(f"\nFull report: {report_path}")
Data Extraction
The data extraction pipeline converts downloaded HTML snapshots into structured tabular data, handling the evolution of FBI NDIS reporting formats across different time periods.
Extraction Overview
The extraction system processes three distinct eras of NDIS reporting:
Pre-2007 Era: Basic statistics without date metadata or arrestee data
2007-2011 Era: Includes “as of” dates but no arrestee profiles
Post-2012 Era: Complete format with all profile types and consistent dating
Key Features:
Era-Aware Processing: Automatically routes files to appropriate parsers based on timestamp
Metadata Recovery: Extracts report dates from “as of” statements when available
Complete Traceability: Links each record to its source HTML file and original URL
Robust Error Handling: Processes files individually to prevent single failures from stopping the entire batch
Core Parser Functions
Essential text processing utilities for NDIS data extraction:
HTML Cleaning: Removes navigation, scripts, and styling elements to focus on data content
Date Extraction: Identifies and parses “as of” dates using multiple pattern variations
Text Normalization: Standardizes whitespace and jurisdiction name formatting
Encoding Handling: Manages various character encodings found in historical snapshots
Show setup and normalization functions code
def extract_ndis_metadata(html_content):""" Extract key metadata from NDIS HTML content including report dates Returns: -------- dict: - report_month: Month from "as of" statement (None if not found) - report_year: Year from "as of" statement (None if not found) - clean_text: Normalized text content """# Multiple patterns to catch different "as of" formats date_patterns = [r'[Aa]s of ([A-Za-z]+)(\d{4})', # "as of November 2008"r'[Aa]s of ([A-Za-z]+)(\d{1,2}), (\d{4})', # "as of November 15, 2008"r'Statistics as of ([A-Za-z]+)(\d{4})', # "Statistics as of November 2008"r'Statistics as of ([A-Za-z]+)(\d{1,2}), (\d{4})'# "Statistics as of November 15, 2008" ] report_month =None report_year =None# Find first occurrence of any date patternfor pattern in date_patterns: date_match = re.search(pattern, html_content)if date_match: month_str = date_match.group(1)iflen(date_match.groups()) ==2: # Month + Year only year_str = date_match.group(2)else: # Month + Day + Year year_str = date_match.group(3)# Convert month name to numbertry: month_num = pd.to_datetime(f"{month_str} 1, 2000").month report_month = month_num report_year =int(year_str)breakexcept:continue# Clean HTML and normalize text soup = BeautifulSoup(html_content, 'lxml')# Remove scripts, styles, and navigation elementsfor element in soup(['script', 'style', 'nav', 'header', 'footer']): element.decompose()# Get clean text with normalized whitespace clean_text = re.sub(r'\s+', ' ', soup.get_text(' ', strip=True))return {'report_month': report_month,'report_year': report_year, 'clean_text': clean_text }def standardize_jurisdiction_name(name):""" Clean and standardize jurisdiction names for consistency """ifnot name:return name# Remove common prefixes and suffixes name = re.sub(r'^.*?(Back to top|Tables by NDIS Participant|ation\.)\s*', '', name, flags=re.I).strip()# Standardize known variants replacements = {'D.C./FBI Lab': 'DC/FBI Lab','D.C./Metro PD': 'DC/Metro PD', 'US Army': 'U.S. Army','D.C.': 'DC' }for old, new in replacements.items(): name = name.replace(old, new)return name.strip()def extract_original_url_from_filename(html_file):""" Reconstruct original URL from filename and timestamp """ filename = html_file.name timestamp = filename.split('_')[0] # Get timestamp part# Determine URL pattern based on filename suffixif filename.endswith('_ndis.html'):# Post-2007 consolidated format - use most common URL patternreturn"https://www.fbi.gov/services/laboratory/biometric-analysis/codis/ndis-statistics"else:# Pre-2007 state-specific format state_code = filename.split('_')[1].replace('.html', '')returnf"http://www.fbi.gov/hq/lab/codis/{state_code}.htm"
Era-Specific Parsers
Time-period-adapted parsing logic that accounts for format evolution:
Pre-2007 Parser:
Extracts basic statistics from state-specific pages
Uses timestamp-derived year (no report dates available)
Sets arrestee counts to 0 (not reported in this era)
Handles missing NDIS labs and investigations data
2008-2011 Parser:
Processes consolidated pages with “Back to top” section dividers
Extracts month and year from report dates
Handles missing arrestee data (sets to 0)
Multiple pattern matching for jurisdiction identification
2012-2016 Parser:
First era with arrestee data extraction
Processes consolidated pages with “Back to top” section dividers
Multiple pattern matching for jurisdiction identification
Complete jurisdiction coverage with standardized names
Post-2017 Parser:
Modern format with consistent structure and all fields
Robust regex pattern for reliable extraction
Full feature extraction including arrestee profiles
Complete jurisdiction coverage with standardized names
Show parser functions code
def parse_pre2007_ndis(text, timestamp, html_file, report_month=None, report_year=None):""" Parse NDIS snapshots from 2001-2007 era (state-specific pages) HTML has table structure with state name followed by data rows """ records = []# Clean up the text for better matching text = re.sub(r'\s+', ' ', text)# Try multiple patterns to extract state name jurisdiction =None# Pattern 1: State name in large font (from graphic alt text or heading)# Looking for patterns like "Graphic of Pennsylvania Pennsylvania" or just the state name state_pattern1 =r'(?:Graphic of|alt=")([A-Z][a-z]+(?:\s+[A-Z][a-z]+)*?)(?:"|>|\s+Offender)' state_match = re.search(state_pattern1, text, re.IGNORECASE)if state_match: jurisdiction = state_match.group(1).strip()# Pattern 2: Try to extract from filename as fallbackifnot jurisdiction:# Extract state code from filename (e.g., "20010715040342_pa.html") filename = html_file.name state_code_match = re.search(r'_([a-z]{2,5})\.html$', filename)if state_code_match: state_code = state_code_match.group(1)# Map common state codes to names state_map = {'pa': 'Pennsylvania', 'nc': 'North Carolina', 'ct': 'Connecticut','wv': 'West Virginia', 'ks': 'Kansas', 'nd': 'North Dakota','wy': 'Wyoming', 'ky': 'Kentucky', 'la': 'Louisiana','dc': 'DC/FBI Lab', 'de': 'Delaware', 'ne': 'Nebraska','sc': 'South Carolina', 'tn': 'Tennessee', 'ma': 'Massachusetts','fl': 'Florida', 'nh': 'New Hampshire', 'sd': 'South Dakota','me': 'Maine', 'hi': 'Hawaii', 'nm': 'New Mexico','al': 'Alabama', 'tx': 'Texas', 'mi': 'Michigan','ut': 'Utah', 'ar': 'Arkansas', 'az': 'Arizona','mo': 'Missouri', 'ny': 'New York', 'mn': 'Minnesota','vt': 'Vermont', 'id': 'Idaho', 'oh': 'Ohio','ok': 'Oklahoma', 'or': 'Oregon', 'ca': 'California','il': 'Illinois', 'wi': 'Wisconsin', 'ms': 'Mississippi','wa': 'Washington', 'mt': 'Montana', 'in': 'Indiana','co': 'Colorado', 'va': 'Virginia', 'ga': 'Georgia','ak': 'Alaska', 'md': 'Maryland', 'nj': 'New Jersey','nv': 'Nevada', 'ri': 'Rhode Island', 'ia': 'Iowa','army': 'U.S. Army' } jurisdiction = state_map.get(state_code, state_code.upper())if jurisdiction: jurisdiction = standardize_jurisdiction_name(jurisdiction)# Extract individual values with more flexible patterns# These patterns work with the table structure in your example offender_match = re.search(r'Offender\s+Profiles?\s+([\d,]+)', text, re.IGNORECASE) forensic_match = re.search(r'Forensic\s+(?:Samples?|Profiles?)\s+([\d,]+)', text, re.IGNORECASE)# NDIS labs can appear as "NDIS Participating Labs" or just "Number of CODIS Labs" ndis_labs_match = re.search(r'(?:NDIS\s+Participating\s+Labs?|Number\s+of\s+CODIS\s+Labs?)\s+(\d+)', text, re.IGNORECASE) investigations_match = re.search(r'Investigations?\s+Aided\s+([\d,]+)', text, re.IGNORECASE)if offender_match and forensic_match: records.append({'timestamp': timestamp,'report_month': None, # Not available pre-2007'report_year': None, # Not available pre-2007'jurisdiction': jurisdiction,'offender_profiles': int(offender_match.group(1).replace(',', '')),'arrestee': 0, # Not reported pre-2007'forensic_profiles': int(forensic_match.group(1).replace(',', '')),'ndis_labs': int(ndis_labs_match.group(1)) if ndis_labs_match else0,'investigations_aided': int(investigations_match.group(1).replace(',', '')) if investigations_match else0 })return recordsdef parse_2008_2011_ndis(text, timestamp, html_file, report_month=None, report_year=None):""" Parse NDIS snapshots from 2008-2011 era Consolidated page with state anchors and "Back to top" links No arrestee data in this period """ records = []# Clean up the text text = re.sub(r'\s+', ' ', text)# Split by "Back to top" to isolate each state section sections = re.split(r'Back\s+to\s+top', text, flags=re.IGNORECASE)for section in sections:# Look for state name pattern (appears as anchor or bold text)# Try multiple patterns to catch different HTML formats jurisdiction =None# Pattern 1: <a name="State"></a><strong>State</strong> state_match = re.search(r'<a\s+name="([^"]+)"[^>]*>.*?(?:<strong>|<b>)\s*([A-Z][^<]+?)(?:</strong>|</b>)', section, re.IGNORECASE)if state_match: jurisdiction = state_match.group(2).strip()# Pattern 2: Just the state name in bold/strong tags before "Statistical Information"ifnot jurisdiction: state_match = re.search(r'(?:<strong>|<b>)\s*([A-Z][^<]+?)(?:</strong>|</b>).*?Statistical\s+Information', section, re.IGNORECASE)if state_match: jurisdiction = state_match.group(1).strip()# Pattern 3: State name without tags before "Statistical Information"ifnot jurisdiction: state_match = re.search(r'([A-Z][a-z]+(?:\s+[A-Z][a-z]+)*)\s+Statistical\s+Information', section)if state_match: jurisdiction = state_match.group(1).strip()if jurisdiction: jurisdiction = standardize_jurisdiction_name(jurisdiction)# Extract values offender_match = re.search(r'Offender\s+Profiles?\s+([\d,]+)', section, re.IGNORECASE) forensic_match = re.search(r'Forensic\s+(?:Samples?|Profiles?)\s+([\d,]+)', section, re.IGNORECASE) ndis_labs_match = re.search(r'NDIS\s+Participating\s+Labs?\s+(\d+)', section, re.IGNORECASE) investigations_match = re.search(r'Investigations?\s+Aided\s+([\d,]+)', section, re.IGNORECASE)if offender_match and forensic_match: records.append({'timestamp': timestamp,'report_month': report_month,'report_year': report_year,'jurisdiction': jurisdiction,'offender_profiles': int(offender_match.group(1).replace(',', '')),'arrestee': 0, # Not reported 2008-2011'forensic_profiles': int(forensic_match.group(1).replace(',', '')),'ndis_labs': int(ndis_labs_match.group(1)) if ndis_labs_match else0,'investigations_aided': int(investigations_match.group(1).replace(',', '')) if investigations_match else0 })return recordsdef parse_2012_2016_ndis(text, timestamp, html_file, report_month=None, report_year=None):""" Parse NDIS snapshots from 2012-2016 era Includes arrestee data for the first time """ records = []# Clean up the text text = re.sub(r'\s+', ' ', text)# Split by "Back to top" to isolate each state section sections = re.split(r'Back\s+to\s+top', text, flags=re.IGNORECASE)for section in sections: jurisdiction =None# Look for state name patterns# Pattern 1: <a name="State"></a><b>State</b> state_match = re.search(r'<a\s+name="([^"]+)"[^>]*>.*?<b>([^<]+?)</b>', section, re.IGNORECASE)if state_match: jurisdiction = state_match.group(2).strip()# Pattern 2: Just bold state nameifnot jurisdiction: state_match = re.search(r'<b>([A-Z][^<]+?)</b>.*?Statistical\s+Information', section, re.IGNORECASE)if state_match: jurisdiction = state_match.group(1).strip()# Pattern 3: State name without tagsifnot jurisdiction: state_match = re.search(r'([A-Z][a-z]+(?:\s+[A-Z][a-z]+)*)\s+Statistical\s+Information', section)if state_match: jurisdiction = state_match.group(1).strip()if jurisdiction: jurisdiction = standardize_jurisdiction_name(jurisdiction)# Extract values INCLUDING arrestee which appears starting 2012 offender_match = re.search(r'Offender\s+Profiles?\s+([\d,]+)', section, re.IGNORECASE) arrestee_match = re.search(r'Arrestee\s+([\d,]+)', section, re.IGNORECASE) forensic_match = re.search(r'Forensic\s+Profiles?\s+([\d,]+)', section, re.IGNORECASE) ndis_labs_match = re.search(r'NDIS\s+Participating\s+Labs?\s+(\d+)', section, re.IGNORECASE) investigations_match = re.search(r'Investigations?\s+Aided\s+([\d,]+)', section, re.IGNORECASE)if offender_match and forensic_match: records.append({'timestamp': timestamp,'report_month': report_month,'report_year': report_year,'jurisdiction': jurisdiction,'offender_profiles': int(offender_match.group(1).replace(',', '')),'arrestee': int(arrestee_match.group(1).replace(',', '')) if arrestee_match else0,'forensic_profiles': int(forensic_match.group(1).replace(',', '')),'ndis_labs': int(ndis_labs_match.group(1)) if ndis_labs_match else0,'investigations_aided': int(investigations_match.group(1).replace(',', '')) if investigations_match else0 })return recordsdef parse_post2017_ndis(text, timestamp, html_file, report_month=None, report_year=None):""" Parse NDIS snapshots from 2017+ era Modern format with consistent structure and all fields Keep using your existing working pattern for this era """ records = []# This is your existing working pattern - don't change it pattern = re.compile(r'([A-Z][\w\s\.\-\'\/&\(\)]+?)Statistical Information'r'.*?Offender Profiles\s+([\d,]+)'r'.*?Arrestee\s+([\d,]+)'r'.*?Forensic Profiles\s+([\d,]+)'r'.*?NDIS Participating Labs\s+(\d+)'r'.*?Investigations Aided\s+([\d,]+)', re.IGNORECASE | re.DOTALL )for match in pattern.finditer(text): records.append({'timestamp': timestamp,'report_month': report_month,'report_year': report_year,'jurisdiction': standardize_jurisdiction_name(match.group(1)),'offender_profiles': int(match.group(2).replace(',', '')),'arrestee': int(match.group(3).replace(',', '')),'forensic_profiles': int(match.group(4).replace(',', '')),'ndis_labs': int(match.group(5)),'investigations_aided': int(match.group(6).replace(',', '')) })return records
Output Schema
Each extracted record contains the following standardized fields:
Field
Description
Availability
timestamp
Wayback capture timestamp (YYYYMMDDHHMMSS)
All eras
report_month
Month from “as of” statement
2007+ only
report_year
Year from “as of” statement
2007+ only
jurisdiction
Standardized state/agency name
All eras
offender_profiles
DNA profiles from convicted offenders
All eras
arrestee
DNA profiles from arrestees
2012+ only
forensic_profiles
Crime scene DNA profiles
All eras
ndis_labs
Number of participating laboratories
All eras
investigations_aided
Cases assisted by DNA matches
All eras
Batch Processing
The complete extraction workflow:
File Discovery
Scans download directory for HTML files
Sorts chronologically for consistent processing
Tracks progress with detailed logging
Individual File Processing
Reads HTML content with encoding fallback
Extracts metadata and cleans content
Routes to era-appropriate parser based on timestamp