Processing Murphy & Tong FOIA Documents about State DNA Database Racial Composition
Author
Tina Lasisi | Edit: João P. Donadio
Published
November 9, 2025
1 Overview
This document details the processing of Freedom of Information Act (FOIA) responses from seven U.S. states regarding the demographic composition of their State DNA Index System (SDIS) databases. These responses were obtained by Professor Erin Murphy (NYU Law) in 2018 as part of research on racial disparities in DNA databases.
2 Materials and Methods
2.1 Data Sources
2.1.1 Raw FOIA Responses
The original FOIA responses are stored in two formats:
PDFs: raw/foia_pdfs/ - Original scanned documents
HTML: raw/foia_html/ - OCR’d versions for easier extraction
Show setup code
# List of required packagesrequired_packages <-c("tidyverse", # Data manipulation and visualization"here", # File path management"knitr", # Dynamic report generation"kableExtra", # Enhanced table formatting"ggplot2", # Data visualization"patchwork", # Plot composition and layout"scales", # Axis scaling and formatting"tidyr", # Data tidying and reshaping"tibble", # Modern data frames"flextable", # Advanced table formatting"DT", # Interactive tables"cowplot", # Plotting composition"sf", # Simple Features for spatial data"usmap"# Mapping US states)# Function to install missing packagesinstall_missing <-function(packages) {for (pkg in packages) {if (!requireNamespace(pkg, quietly =TRUE)) {message(paste("Installing missing package:", pkg))install.packages(pkg, dependencies =TRUE) } }}# Install any missing packagesinstall_missing(required_packages)# Load all packagessuppressPackageStartupMessages({library(tidyverse)library(here)library(knitr)library(kableExtra)library(ggplot2)library(patchwork)library(scales)library(tidyr)library(tibble)library(flextable)library(cowplot)library(sf)library(usmap)})# Verify all packages loaded successfullyloaded_packages <-sapply(required_packages, require, character.only =TRUE)if (all(loaded_packages)) {message("All packages loaded successfully!")} else {warning("The following packages failed to load: ", paste(names(loaded_packages)[!loaded_packages], collapse =", "))}# Display optionsoptions(tibble.width =Inf)options(dplyr.summarise.inform =FALSE)# Path to per-state files (run notebook from analysis/)base_dir <-here("..")per_state <-here("data", "foia", "intermediate")# ------------------------------------------------------------------# 1. Discover available per-state CSV files# ------------------------------------------------------------------state_files <-list.files(per_state, pattern ="*_foia_data\\.csv$", full.names =TRUE)if (length(state_files) ==0) {stop(paste("No per-state FOIA files found in", per_state, ". Check the folder path."))}stem_to_state <-function(stem) { toks <-str_split(stem, "_")[[1]]if ("foia"%in% toks) { toks <- toks[1:(which(toks =="foia") -1)] }paste(tools::toTitleCase(toks), collapse =" ")}states_available <-map_chr(basename(state_files), ~stem_to_state(str_remove(.x, "_foia_data\\.csv")))cat(paste("✓ Found", length(state_files), "per-state files:\n"))for (s in states_available) {cat(paste(" •", s, "\n"))}# ------------------------------------------------------------------# 2. Initialize empty containers for the loop that follows# ------------------------------------------------------------------foia_combined <-tibble()foia_state_metadata <-list()
✓ Found 7 per-state files:
• California
• Florida
• Indiana
• Maine
• Nevada
• South Dakota
• Texas
2.2 Processing workflow
For transparency, each state file is processed independently then merged into a single combined long‑format table (foia_combined):
Load one file per state from data/foia/intermediate/.
Append its rows to foia_combined. A parallel dataframe, foia_state_metadata, records what each state reported (counts, percentages, which categories) and any state-specific characteristics (e.g. Nevada’s “flags” terminology).
Quality‑check each state:
verify that race and gender percentages sum to ≈ 100 % when provided,
confirm that demographic counts sum to the state’s reported total profiles,
calculate any missing counts or percentages and tag those rows value_source = "calculated".
Save outputs
data/foia/final/foia_data_clean.csv — the fully combined tidy table with both reported and calculated values,
data/foia/intermediate/foia_state_metadata.csv — one row per state summarising coverage and caveats. After QC passes, freeze foia_data_clean.csv to data/foia/final/foia_data_clean.csv. Versioned releases are managed via analysis/version_freeze.qmd.
2.3 Helper Functions
The functions below perform each transformation required for harmonizing the state‑level FOIA tables.
2.3.1 Data Processing Helper Functions Reference
Function
Definition
Parameters
load_state()
Loads and preprocesses state FOIA data files, handling numeric conversion and validation
path: File path to state CSV
enhanced_glimpse()
Provides an enhanced data overview with column types, missing values, unique counts, and unique values
df: Input dataframe
fill_demographic_gaps()
Fills missing gender counts and adds Unknown race category when totals permit calculation
df: Input dataframe
add_combined()
Creates Combined offender type by summing Convicted Offender and Arrestee counts when missing
df: Input dataframe
add_percentages()
Derives percentage values from counts for all demographic categories
df: Input dataframe
counts_consistent()
Verifies that demographic counts sum to total_profiles for each offender type
df: Input dataframe
percentages_consistent()
Verifies that percentages sum to 100 ± 0.5% for each category
df: Input dataframe
report_status()
Reports what data types (counts/percentages/both) are available for a category
df: Input dataframe, category: race or gender
verify_category_totals()
Compares demographic sums against reported totals and shows differences
df: Input dataframe
verify_percentage_consistency()
Compares reported vs calculated percentages for consistency
df_combined: Combined dataframe, state_name: State name
calculate_combined_totals()
Calculates Combined totals by summing across offender types
df: Input dataframe, state_name: State name
calculate_percentages()
Calculates percentages from counts for demographic categories
df_combined: Combined dataframe, state_name: State name
calculate_counts_from_percentages()
Calculates counts from percentages for demographic categories
df_combined: Combined dataframe, state_name: State name
standardize_offender_types()
Standardizes offender type names to consistent terminology
df: Input dataframe
prepare_state_for_combined()
Prepares state data for inclusion in combined dataset with proper columns
df: Input dataframe, state_name: State name
format_compact()
Formats large numbers with K/M suffixes for readability
x: Numeric value
create_pie_chart()
Creates pie charts for specific demographic categories
Creates comprehensive pie chart visualizations for all metrics
df_combined: Combined dataframe, state_name: State name
create_demographic_bar_charts()
Creates side-by-side bar charts for gender and race distributions
df_combined: Combined dataframe, state_name: State name
add_state_metadata()
Creates and appends a metadata record capturing state data characteristics including available offender types, demographic categories, data formats, and special features
df: Input dataframe, state_name: State name
update_state_metadata()
Modifies existing state metadata to update QC results (count/percentage consistency) and append validation notes
The following table summarizes the structure and content of the data as originally received from each state prior to any standardization, calculation, or processing.
Only female gender was reported; Non-standard term (Offenders, Caucasian, and African American)
Legend:
CO: Convicted Offender
AR: Arrestee
COMB: Combined Total (all profiles)
Counts + %: Both raw numbers and percentages were provided
2.5 Prepare Combined Dataset
The goal of this step is to transform each state’s raw data into a standardized format before appending it to the master foia_combined DataFrame. This ensures consistency and enables seamless analysis across all seven states.
The ideal, standardized state dataset ready for combination must have the following columns:
Column Name
Description
Example Values
state
The name of the state.
"California", "Florida"
offender_type
The category of offender profile.
"Convicted Offender", "Arrestee", "Combined"
variable_category
The broad demographic category.
"race", "gender", "total", "gender_race"
variable_detailed
The specific value within the category.
"White", "Male", "total_profiles", "Male_White"
value
The numerical value for the metric.
150000, 25.8
value_type
The type of metric the value represents.
"count", "percentage"
value_source
Whether the data was provided or derived.
"reported", "calculated"
Show the master foia_combined dataframe elaboration code
# ------------------------------------------------------------------# Initialize the master foia_combined dataframe with correct schema# This empty structure ensures all state data is appended consistently# ------------------------------------------------------------------foia_combined <-tibble( state =character(),offender_type =character(),variable_category =character(),variable_detailed =character(), value =numeric(),value_type =character(),value_source =character())# Create a data dictionary for foia_combinedschema_dict <-tribble(~Column, ~Type, ~Description, "state", "character", "'California', 'Florida'","offender_type", "character", "'Convicted Offender', 'Arrestee', 'Combined'","variable_category", "character", "'race', 'gender', 'total', 'gender_race'","variable_detailed", "character", "'White', 'Male', 'total_profiles', 'Male_White'","value", "numeric", "150000, 25.8","value_type", "character", "'count', 'percentage'","value_source", "character", "'reported', 'calculated'")# Turn into a nice flextableflextable(schema_dict) %>%autofit() %>%theme_booktabs() %>%set_header_labels(Column ="Column Name",Type ="Data Type",Description ="Example Values to be added" )
Column Name
Data Type
Example Values to be added
state
character
'California', 'Florida'
offender_type
character
'Convicted Offender', 'Arrestee', 'Combined'
variable_category
character
'race', 'gender', 'total', 'gender_race'
variable_detailed
character
'White', 'Male', 'total_profiles', 'Male_White'
value
numeric
150000, 25.8
value_type
character
'count', 'percentage'
value_source
character
'reported', 'calculated'
2.6 Prepare Metadata Documentation Table
This section creates a comprehensive metadata table (foia_state_metadata) to document the original content and structure of each state’s FOIA response before any processing or cleaning was applied.
This serves as a permanent record of data provenance, ensuring transparency and reproducibility by clearly distinguishing between what was provided by the states and what was calculated during analysis.
Key Documentation Captured:
Data Types Provided: Whether each state reported counts, percentages, or both for race, gender, and total profiles.
Offender Categories Reported: Which offender types (Convicted Offender, Arrestee, Combined) were originally included.
Demographic Granularity: Presence of ‘Unknown’ or ‘Other’ categories and gender-race cross-tabulations.
Terminology & Anomalies: Use of non-standard terms (e.g., “flags,” “offenders”) and other state-specific reporting notes.
QC Results: Flags for whether cleaned data passes consistency checks (counts sum to totals, percentages sum to ~100%).
Show the foia_state_metadata table elaboration code
# ------------------------------------------------------------------# Initialize the foia_state_metadata as a tibble (not a list of lists)# This makes it easier to add rows and ensures consistent structure.# ------------------------------------------------------------------# Define the full schema for our metadata tablefoia_state_metadata <-tibble(state =character(),race_data_provided =character(),gender_data_provided =character(),total_profiles_provided =character(), convicted_offender_reported =logical(),arrestee_reported =logical(),combined_reported =logical(),has_unknown_category =logical(),has_other_category =logical(),uses_nonstandard_terminology =logical(),provides_crosstabulation =logical(),counts_sum_to_total =logical(),percentages_sum_to_100 =logical(),total_calculated_combined =logical(),notes =character())# Build data dictionary for foia_state_metadataschema_dict_meta <-tribble(~Column, ~Type, ~Description,"state", "character", "State name (e.g., 'California', 'Florida')","race_data_provided", "character", "Race data availability: 'counts', 'percentages', 'both', 'none'","gender_data_provided", "character", "Gender data availability: 'counts', 'percentages', 'both', 'none'","total_profiles_provided", "character", "Total profiles availability: 'counts', 'percentages', 'both', 'none'","convicted_offender_reported", "logical", "Was convicted offender data reported?","arrestee_reported", "logical", "Was arrestee data reported?","combined_reported", "logical", "Was combined category reported?","has_unknown_category", "logical", "Does the state include 'Unknown' category?","has_other_category", "logical", "Does the state include 'Other' category?","uses_nonstandard_terminology", "logical", "Does the state use non-standard terms?","provides_crosstabulation", "logical", "Does the state provide crosstabs (e.g., gender x race)?","counts_sum_to_total", "logical", "Do reported counts sum to the total?","percentages_sum_to_100", "logical", "Do reported percentages sum to ~100%?","total_calculated_combined", "logical", "Did we calculate combined total manually?","notes", "character", "Free-text notes for state-specific caveats")# Render with flextableflextable(schema_dict_meta) %>%autofit() %>%theme_booktabs() %>%set_header_labels(Column ="Column Name",Type ="Data Type",Description ="Meaning" )
Column Name
Data Type
Meaning
state
character
State name (e.g., 'California', 'Florida')
race_data_provided
character
Race data availability: 'counts', 'percentages', 'both', 'none'
gender_data_provided
character
Gender data availability: 'counts', 'percentages', 'both', 'none'
total_profiles_provided
character
Total profiles availability: 'counts', 'percentages', 'both', 'none'
convicted_offender_reported
logical
Was convicted offender data reported?
arrestee_reported
logical
Was arrestee data reported?
combined_reported
logical
Was combined category reported?
has_unknown_category
logical
Does the state include 'Unknown' category?
has_other_category
logical
Does the state include 'Other' category?
uses_nonstandard_terminology
logical
Does the state use non-standard terms?
provides_crosstabulation
logical
Does the state provide crosstabs (e.g., gender x race)?
counts_sum_to_total
logical
Do reported counts sum to the total?
percentages_sum_to_100
logical
Do reported percentages sum to ~100%?
total_calculated_combined
logical
Did we calculate combined total manually?
notes
character
Free-text notes for state-specific caveats
3 State-by-state Standardization
Each state is processed individually to standardize terminology, fill gaps, and calculate Combined totals where necessary.
3.1 California (CA)
Overview: California supplies counts only for gender and race plus a separate total for each offender type; no percentages are reported.
3.1.1 Examine Raw Data
Establish a baseline understanding of the data exactly as it was received.
Column
Type
Rows
Missing
Unique
Unique_Values
state
character
16
0
1
California
offender_type
character
16
0
2
Convicted Offender, Arrestee
variable_category
character
16
0
3
total, gender, race
variable_detailed
character
16
0
8
total_profiles, Female, Male, Unknown, African American, Caucasian, Hispanic, Asian
Runs the first quality check using the verify_category_totals() and counts_consistent() functions.
This identifies any immediate discrepancies, such as the sum of demographic counts not matching the reported total profiles, which flags data issues that need to be resolved.
Verifying that demographic counts match reported totals:
offender_type
variable_category
total_profiles
sum_counts
difference
Arrestee
gender
751822
751822
0
Arrestee
race
751822
655695
96127
Convicted Offender
gender
2019899
2019899
0
Convicted Offender
race
2019899
1626012
393887
Counts consistency check on raw data:
All counts consistent: FALSE
3.1.3 Address Data Gaps
3.1.3.1 Create Unknown Category
“Racial classification is not considered a required field on the collection card; thus, an unknown number of offenders may have no racial classification listed.” — California DOJ FOIA letter, July 10 2018 (raw/foia_pdfs/FOIA_RacialComp_California.pdf)
The 393,887 Convicted Offender profiles and 96,127 Arrestee profiles that do not appear in any of the four reported race categories must belong to an unreported “Unknown” category.
The calculated values are added with a value_source = "calculated" tag to maintain transparency about what was provided versus what was derived.
Show unknown addition code
# Start with the raw dataca_clean <- ca_raw# Add Unknown race category to reconcile totalsca_clean <-fill_demographic_gaps(ca_clean)# Verify the fixcat("Category totals after adding Unknown race category:\n")verify_category_totals(ca_clean) %>%kable() %>%kable_styling()cat("\nCounts consistency after adding Unknown:\n")cat(paste("All counts consistent:", counts_consistent(ca_clean), "\n"))
Category totals after adding Unknown race category:
offender_type
variable_category
total_profiles
sum_counts
difference
Arrestee
gender
751822
751822
0
Arrestee
race
751822
751822
0
Convicted Offender
gender
2019899
2019899
0
Convicted Offender
race
2019899
2019899
0
Counts consistency after adding Unknown:
All counts consistent: TRUE
3.1.3.2 Create Combined Totals
Since California only reported data for “Convicted Offender” and “Arrestee” separately.
This step uses the add_combined() helper function to calculate a new “Combined” offender type by summing the counts from the other two categories.
Show combined addition code
# Calculate Combined totals using helper functionca_clean <-add_combined(ca_clean)cat("✓ Created Combined totals for California\n")# Show the Combined totalcombined_total <- ca_clean %>%filter(offender_type =="Combined", variable_category =="total", variable_detailed =="total_profiles") %>%pull(value)cat(paste("Combined total profiles:", format(combined_total, big.mark =","), "\n"))
✓ Created Combined totals for California
Combined total profiles: 2,771,721
3.1.3.3 Calculate Percentages
Transforms the data from counts into percentages for comparative analysis.
The add_percentages() helper function calculates each demographic group’s proportion relative to its offender type’s total.
A final consistency check ensures all percentages logically sum to approximately 100%.
Show percentage calculation code
# Derive percentages from countsca_clean <-add_percentages(ca_clean)cat("✓ Added percentages for all demographic categories\n")# Check percentage consistencycat("Percentage consistency check:\n")cat(paste("All percentages sum to ~100%:", percentages_consistent(ca_clean), "\n\n"))# Show current data availabilitycat("Final data availability:\n")cat(paste("Race data:", report_status(ca_clean, "race"), "\n"))cat(paste("Gender data:", report_status(ca_clean, "gender"), "\n"))
✓ Added percentages for all demographic categories
Percentage consistency check:
All percentages sum to ~100%: TRUE
Final data availability:
Race data: both
Gender data: both
3.1.3.4 Standardize Terminology
California uses “African American” instead of “Black” and “Caucasian” instead of “White”.
The cleaned data is formatted to match the master schema and appended to the foia_combined dataframe.
Show California data preparation to combined dataset
# Prepare the cleaned data for the combined datasetca_prepared <-prepare_state_for_combined(ca_clean, "California")# Append to the master combined dataframefoia_combined <-bind_rows(foia_combined, ca_prepared)cat(paste0("✓ Appended ", nrow(ca_prepared), " California rows to foia_combined\n"))cat(paste0("✓ Total rows in foia_combined: ", nrow(foia_combined), "\n"))
✓ Appended 51 California rows to foia_combined
✓ Total rows in foia_combined: 51
3.1.5 Document Metadata
The metadata is added with the raw information and updated with the results of the quality checks and a note on the processing steps taken.
Show California data preparation and addition to metadata table
# Add California to the metadata table using the helper functionadd_state_metadata("California", ca_raw)# Update metadata with QC resultsupdate_state_metadata("California", counts_ok =counts_consistent(ca_clean),percentages_ok =percentages_consistent(ca_clean),notes_text ="Added Unknown race category to reconcile totals; calculated Combined totals and all percentages")
✓ Metadata added for: California
✓ Metadata updated for: California
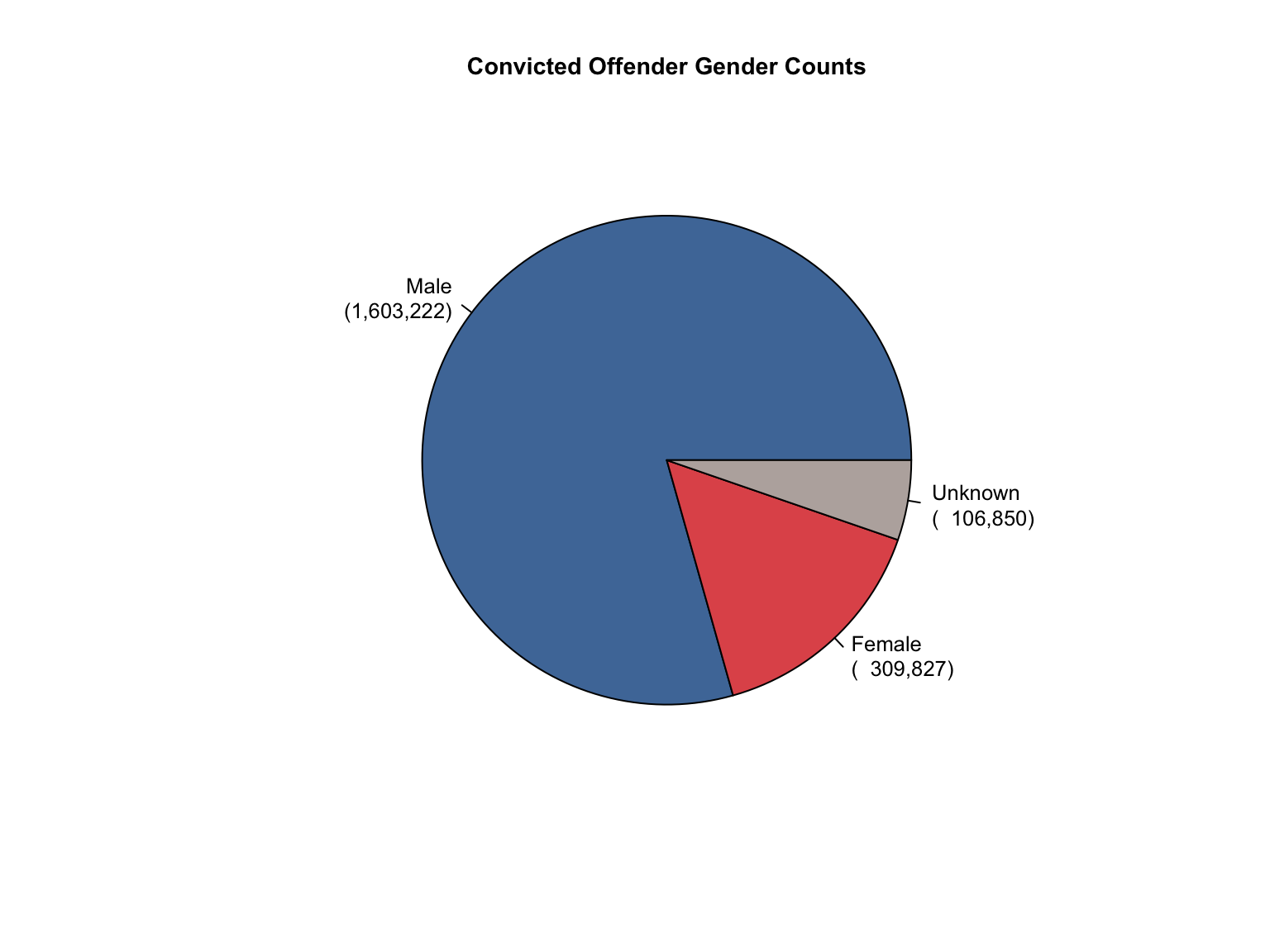
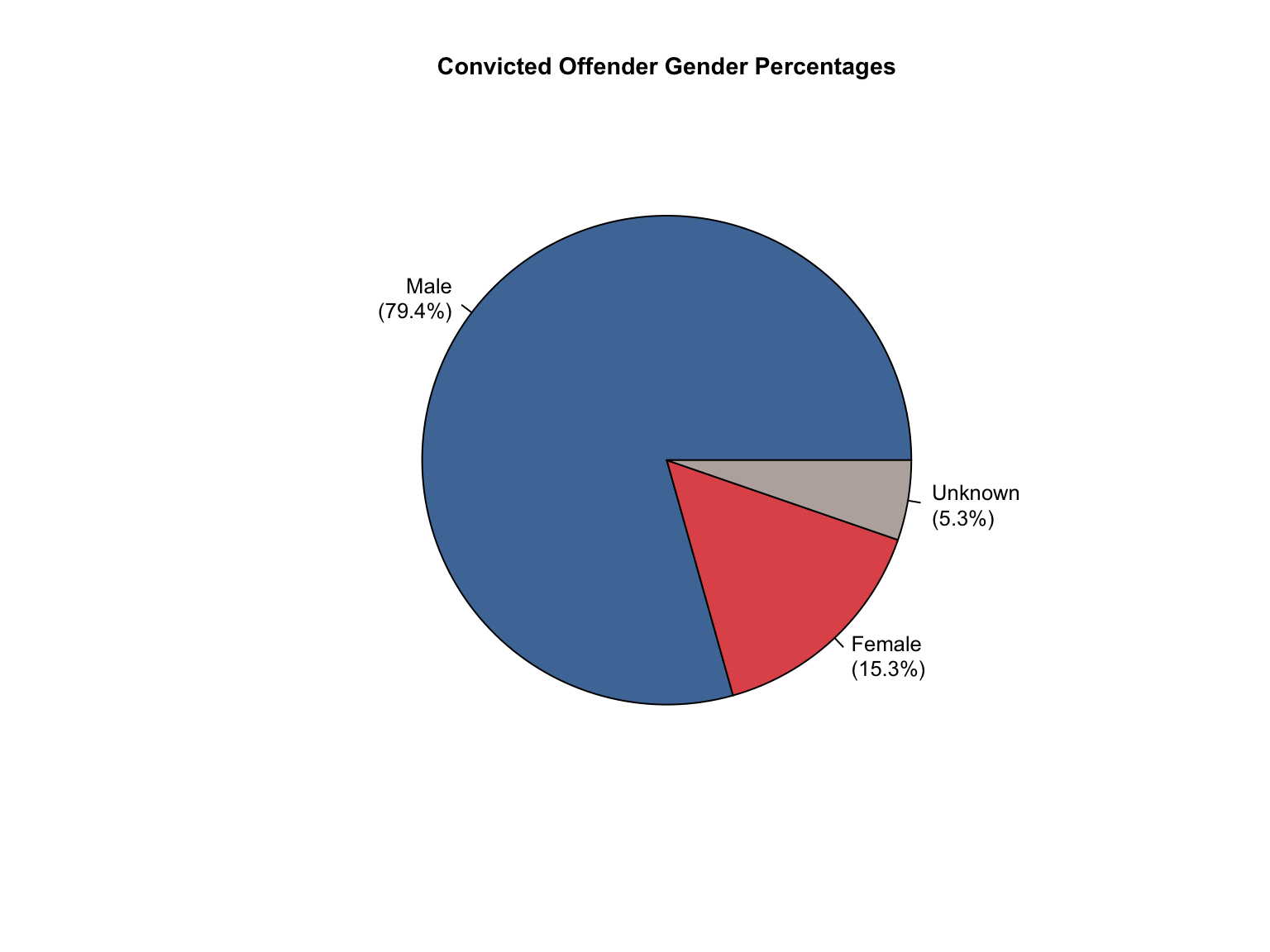
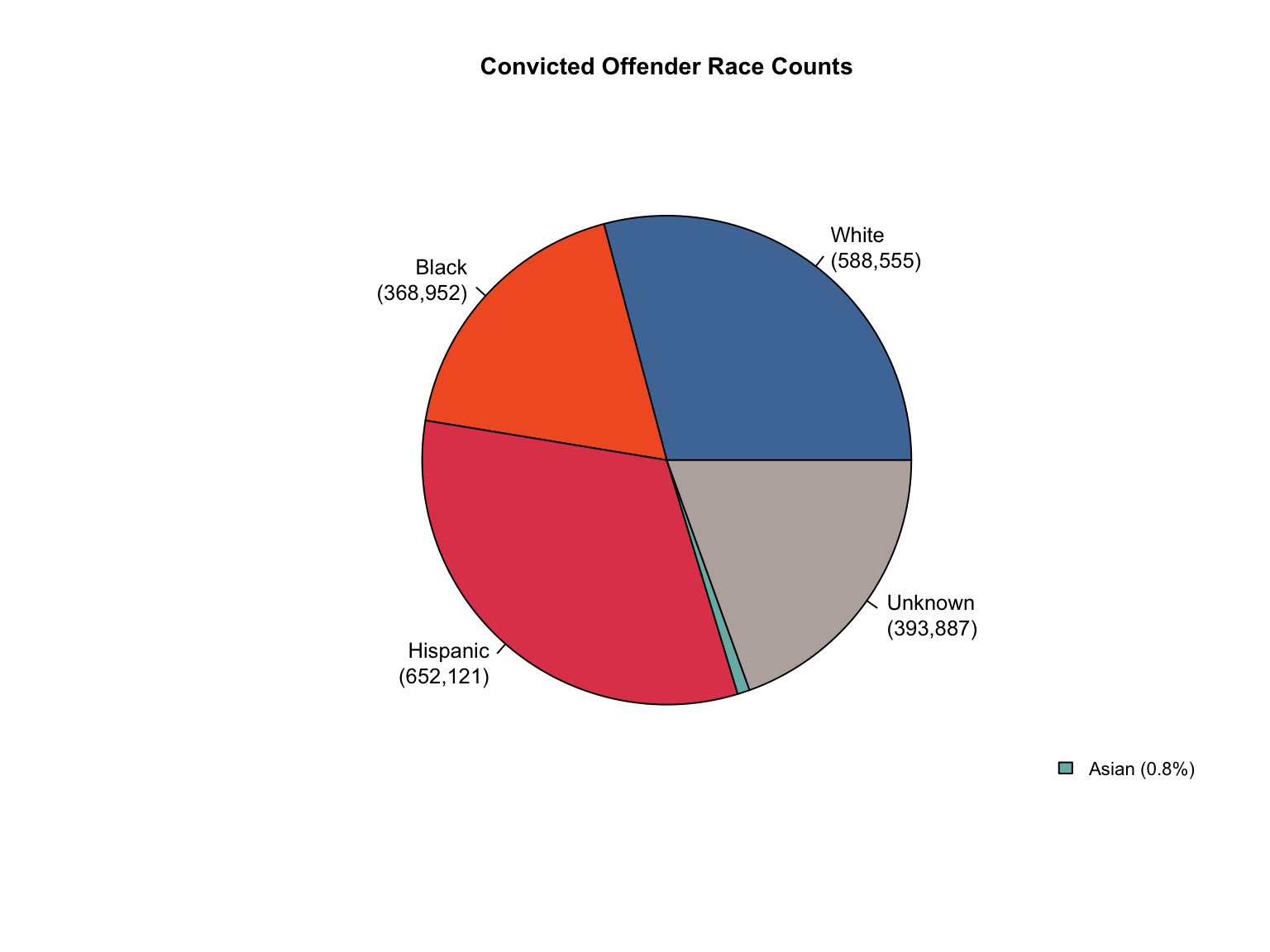
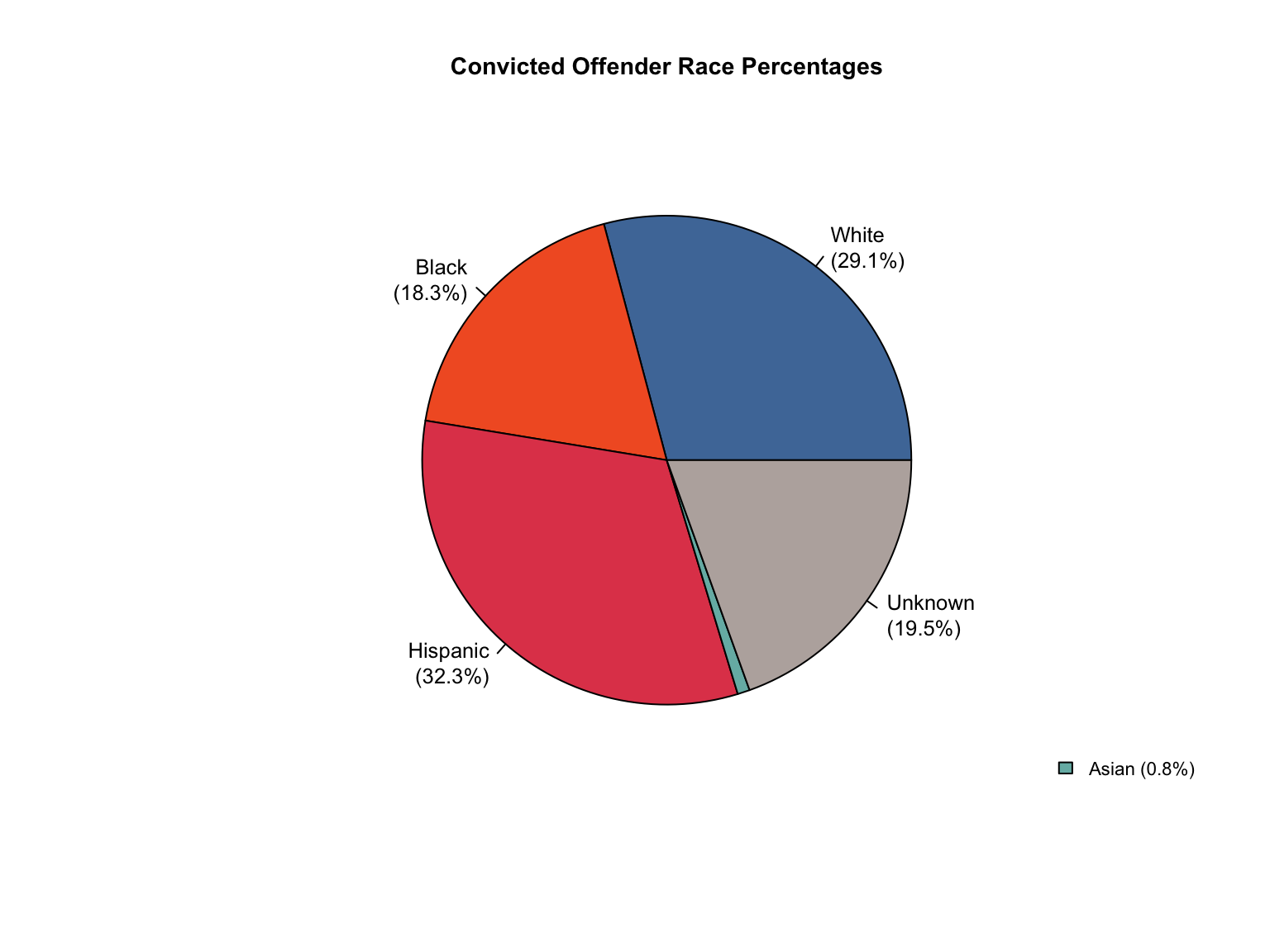
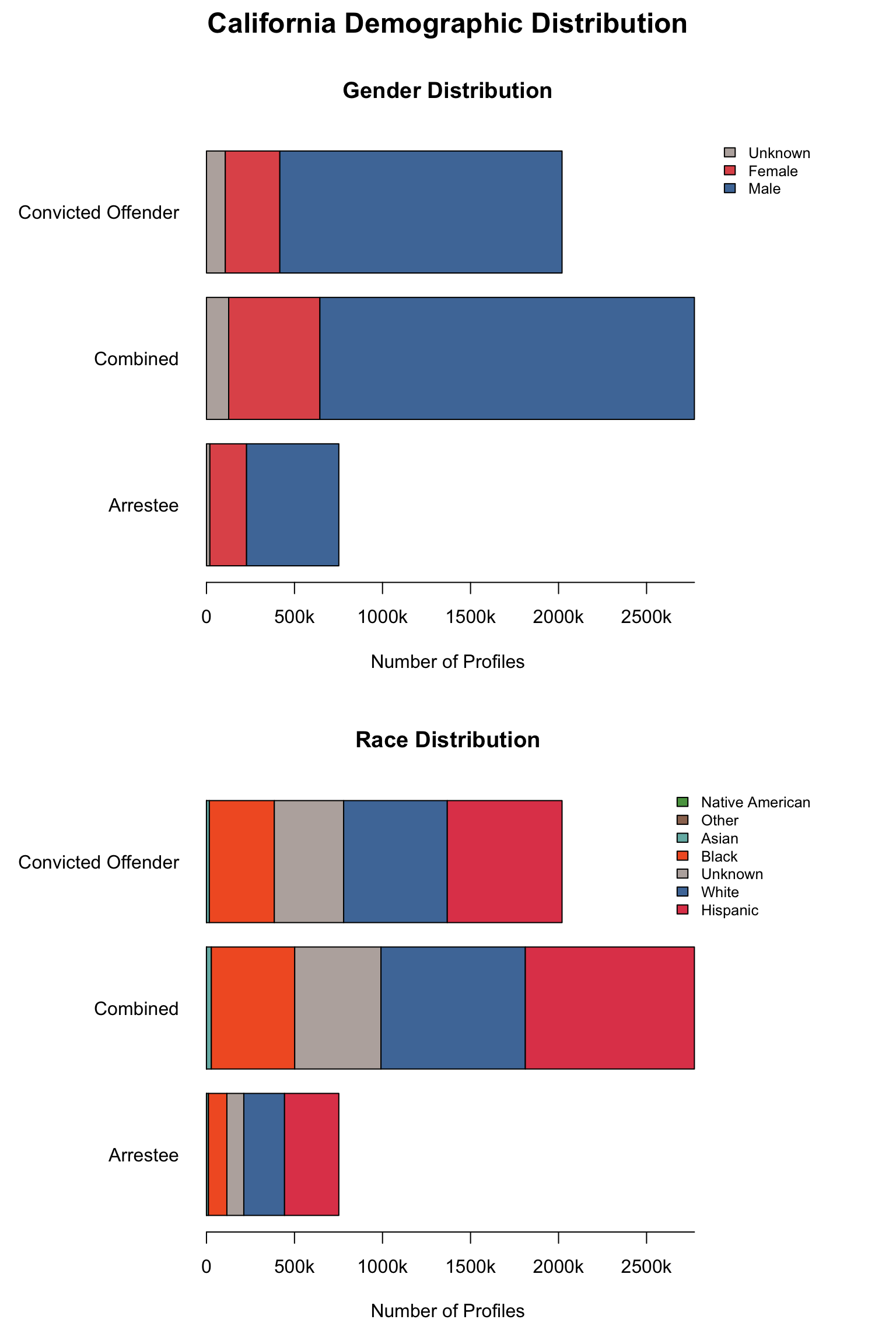
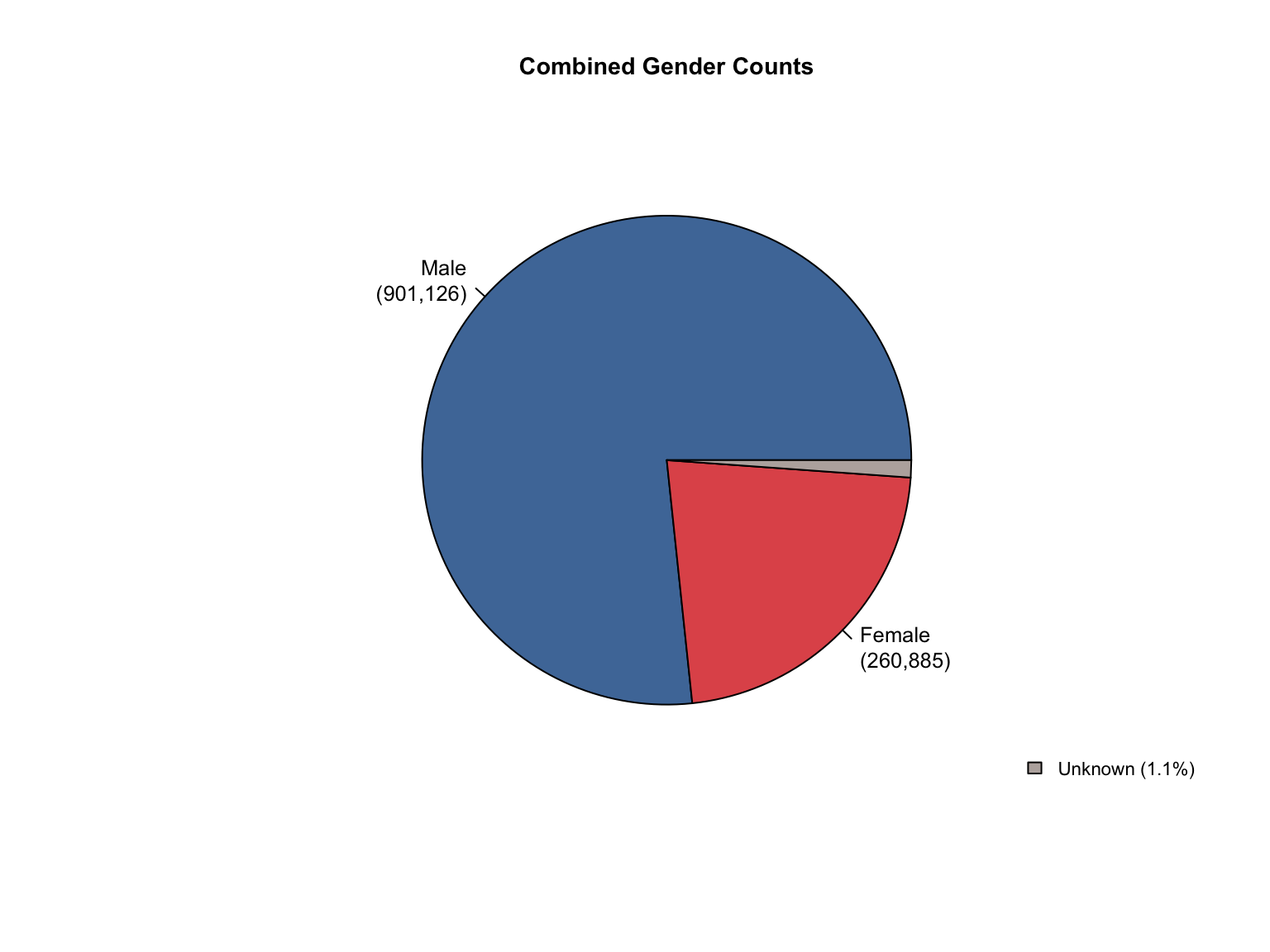
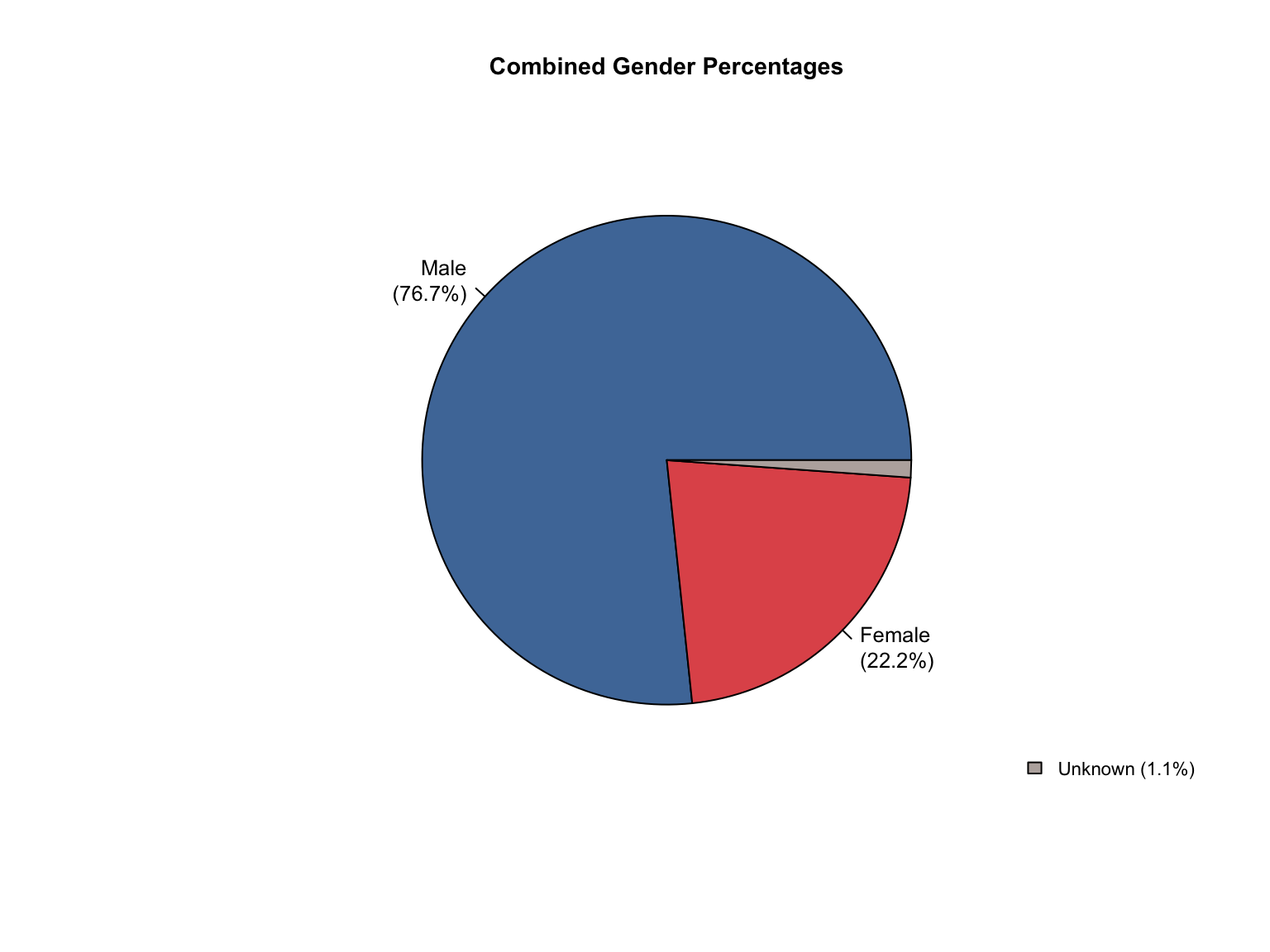
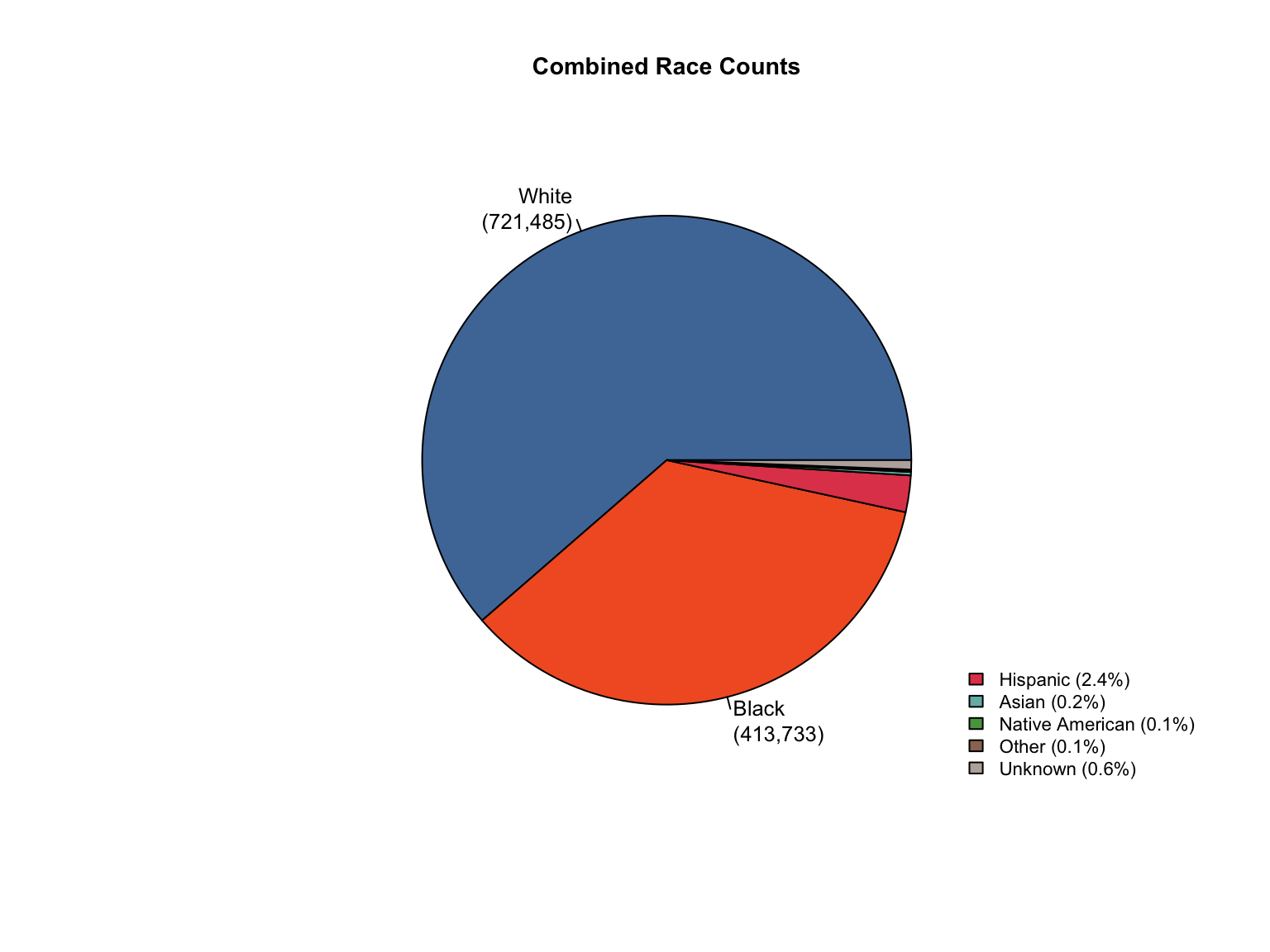
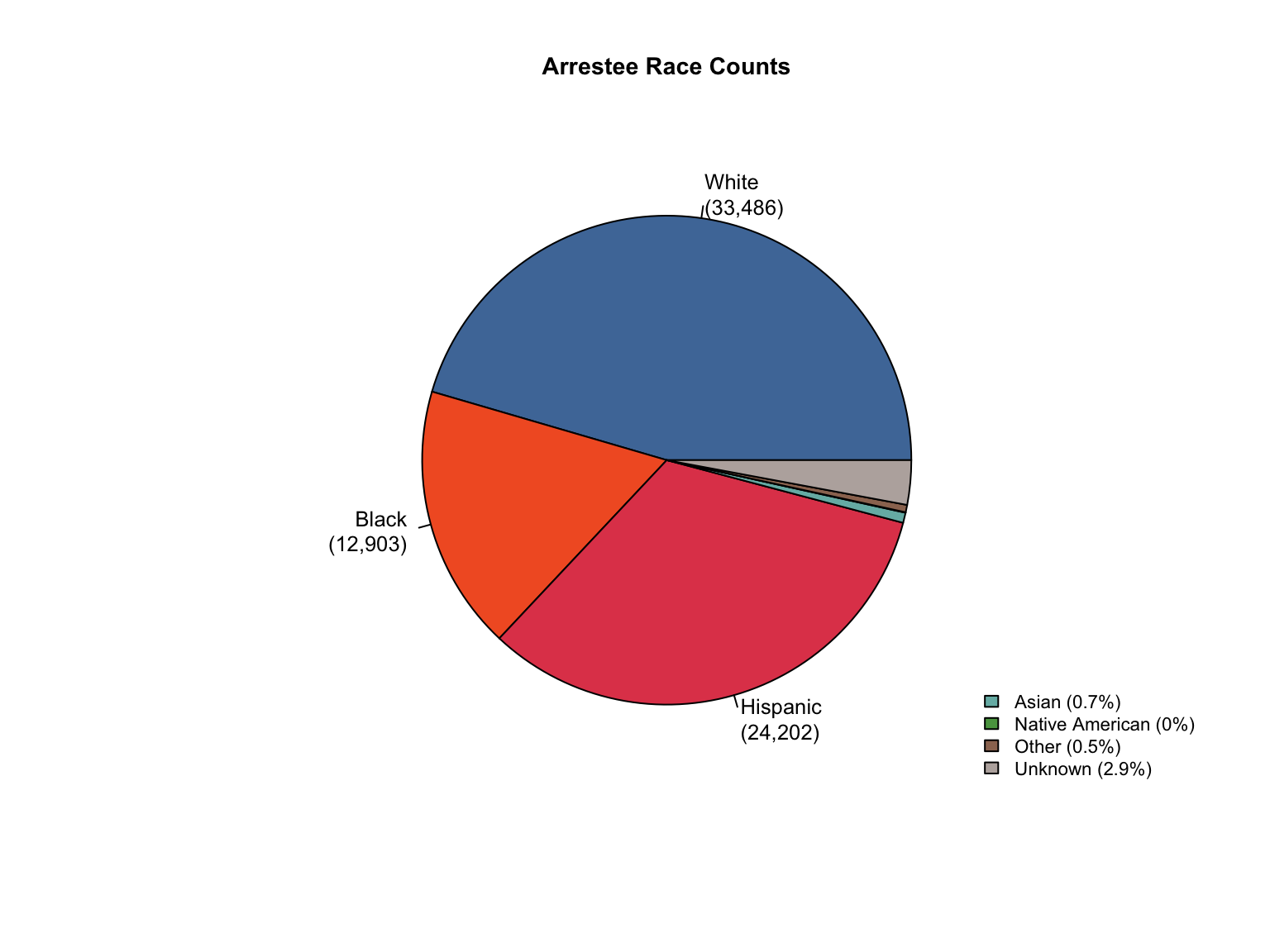
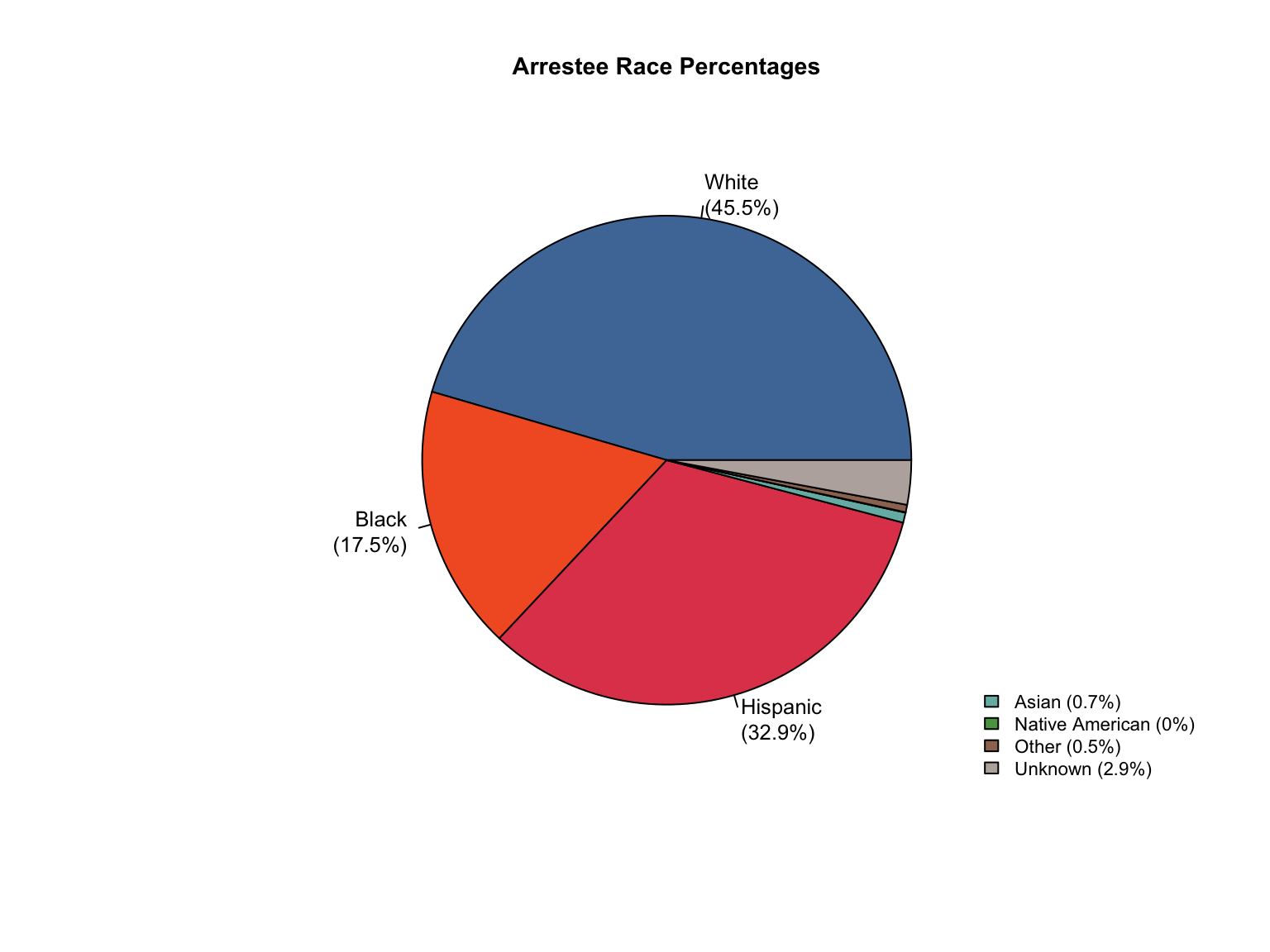
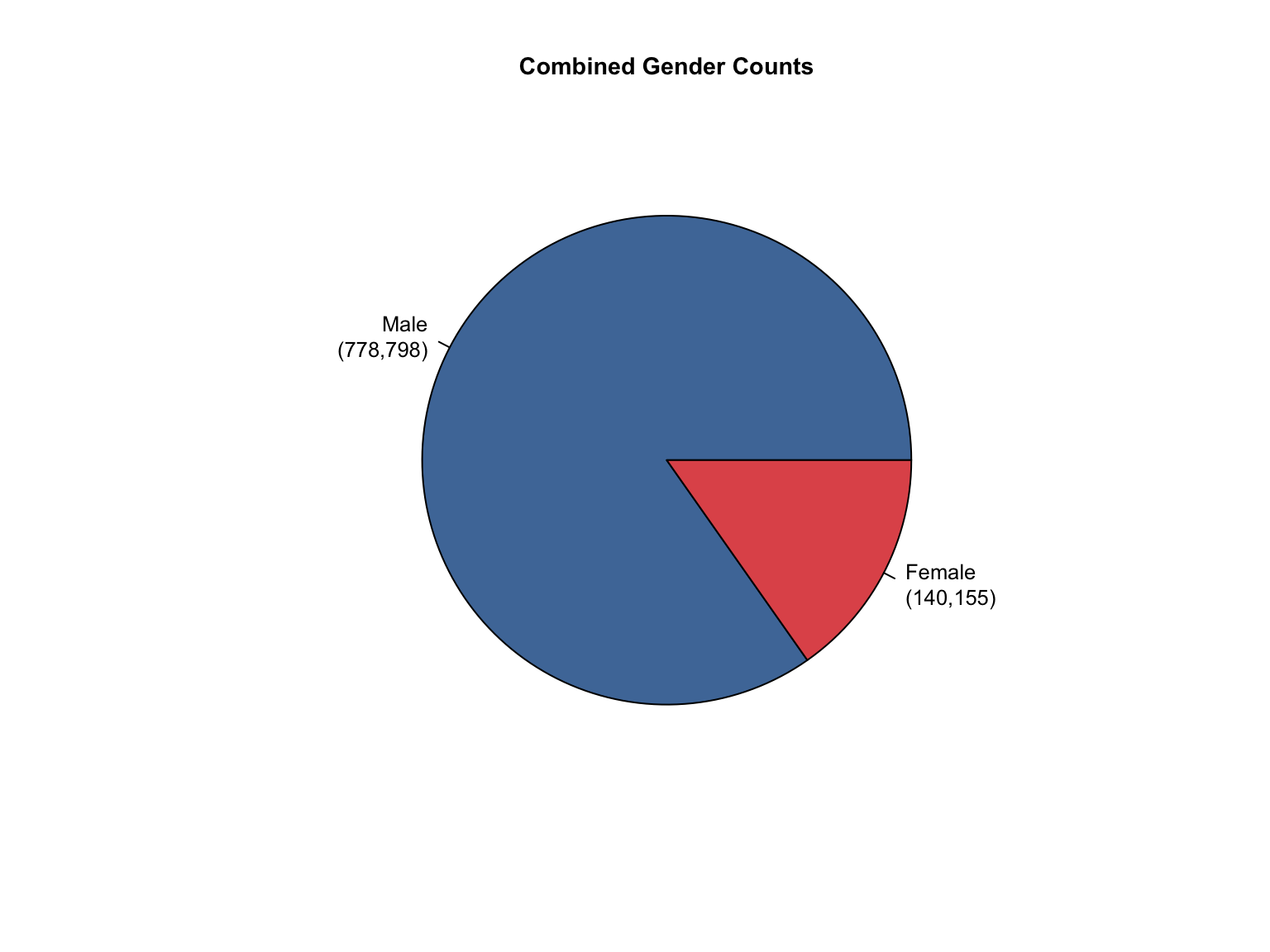
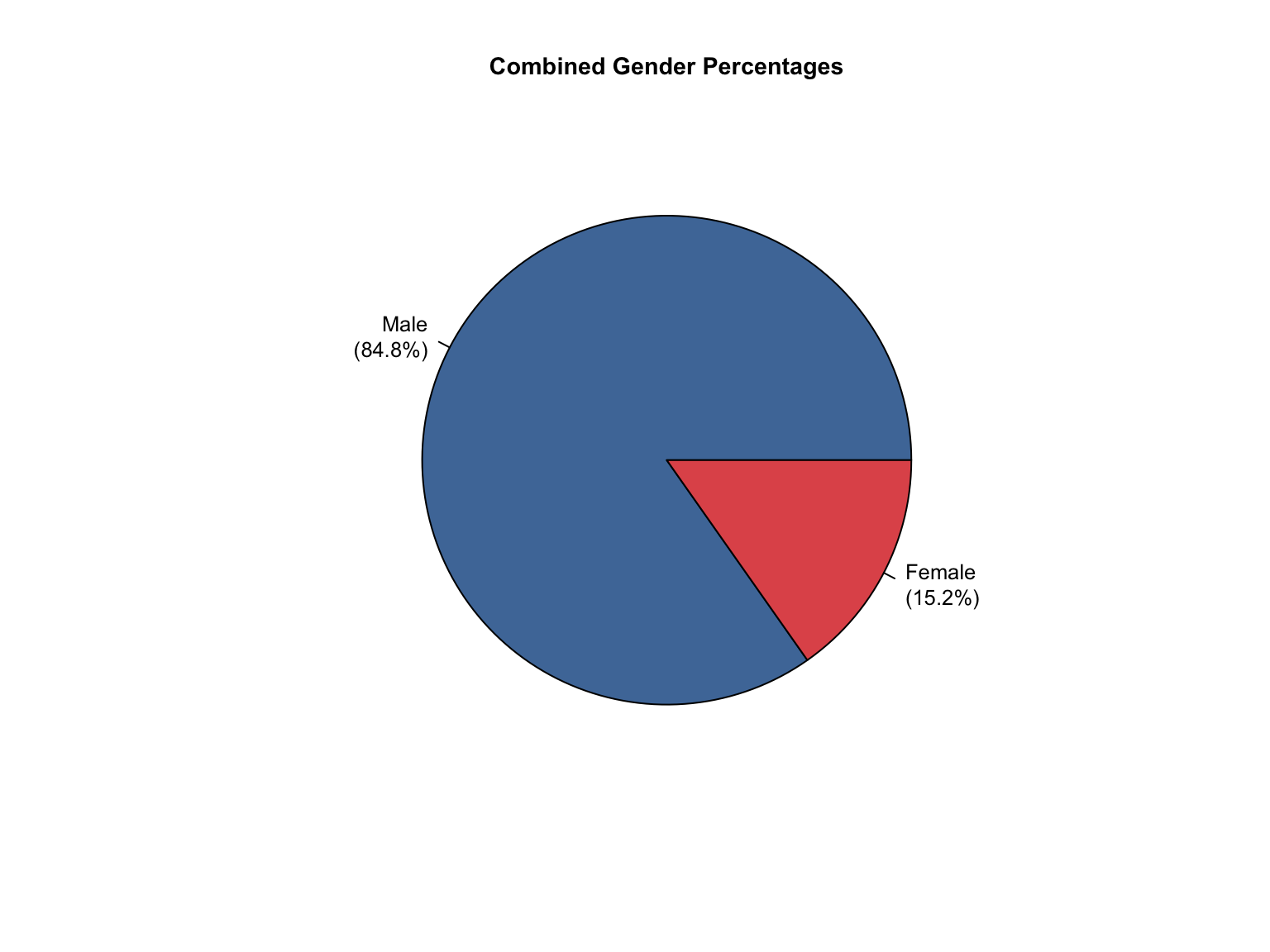
3.1.6 Visualizations
California DNA Database Demographic Distributions
California DNA Database Demographic Distributions
California DNA Database Demographic Distributions
California DNA Database Demographic Distributions
California DNA Database Demographic Distributions
California DNA Database Demographic Distributions
California DNA Database Demographic Distributions
California DNA Database Demographic Distributions
California DNA Database Demographic Distributions
California DNA Database Demographic Distributions
California DNA Database Demographic Distributions
California DNA Database Demographic Distributions
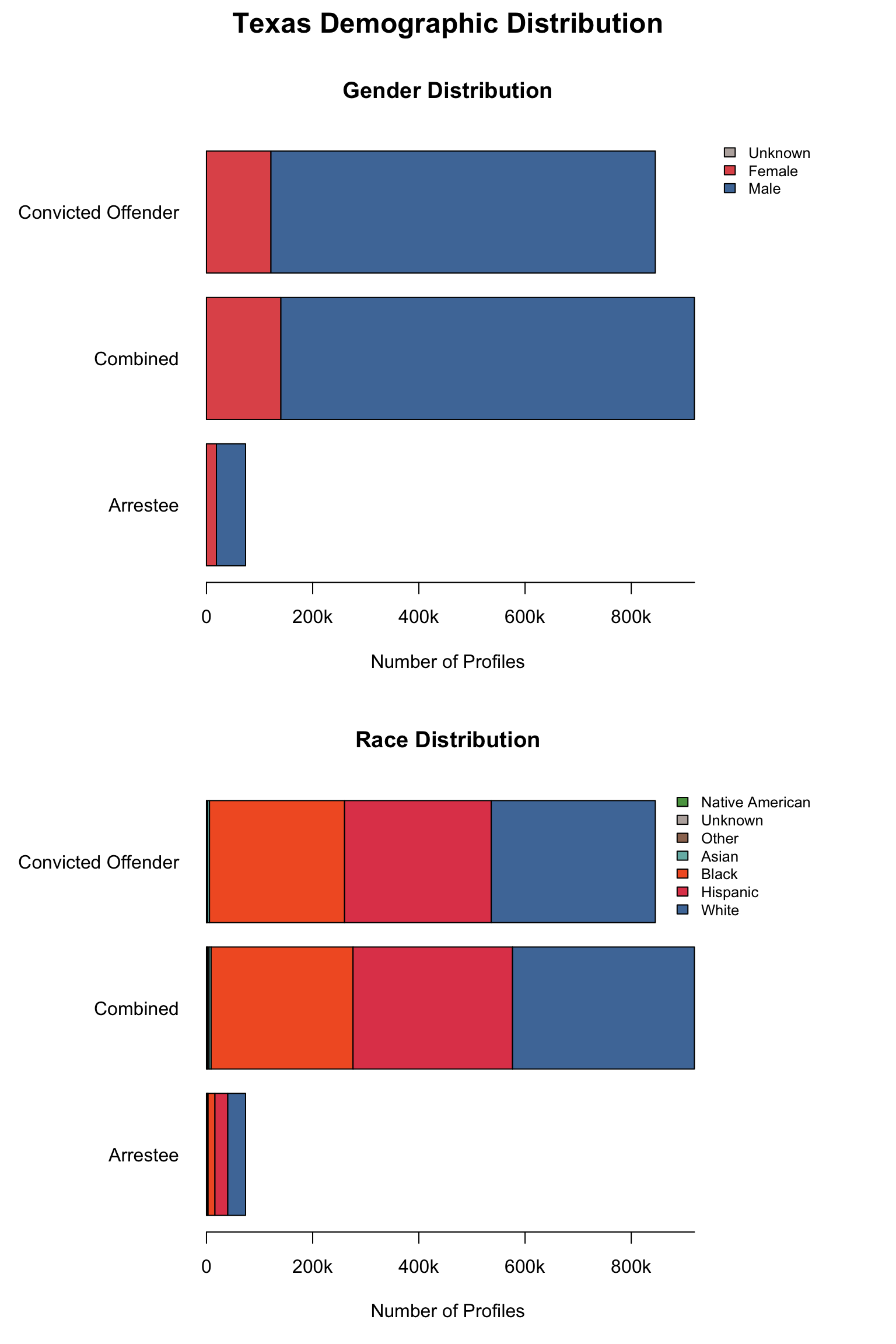
California Demographic Distributions by Offender Type
California data processing complete. The dataset now includes:
✅ Reported data: Counts for Convicted Offender and Arrestee
✅ Calculated additions:
Unknown race category to reconcile reported totals
Combined totals across all offender types
Percentage values for all demographic categories
“Caucasian” and “African American” converted to “White” and “Black”.
✅ Quality checks: All counts and percentages pass consistency validation
✅ Provenance tracking: All values include appropriate value_source indicators
The California data is now standardized and ready for cross-state analysis.
3.2 Florida (FL)
Overview: Florida provides both counts and percentages for gender and race categories and already includes a “Combined” total for all offender types, making it one of the most complete and straightforward datasets.
Only requires to standardize terminology for gender and race categories to match the common data model.
3.2.1 Examine Raw Data
Establish a baseline understanding of the data exactly as it was received.
The Florida data is already complete and consistent. It is formatted to match the master schema and appended to the foia_combined dataframe.
Show Florida data preparation to combined dataset
# Prepare the data for the combined datasetfl_prepared <-prepare_state_for_combined(fl_clean, "Florida")# Append to the master combined dataframefoia_combined <-bind_rows(foia_combined, fl_prepared)cat(paste0("✓ Appended ", nrow(fl_prepared), " Florida rows to foia_combined\n"))cat(paste0("✓ Total rows in foia_combined: ", nrow(foia_combined), "\n"))
✓ Appended 22 Florida rows to foia_combined
✓ Total rows in foia_combined: 73
3.2.5 Document Metadata
The metadata is added with a note that the data was complete and required no processing.
Show Florida data preparation and addition to metadata table
# Add Florida to the metadata table using the helper functionadd_state_metadata("Florida", fl_raw)# Update metadata with QC resultsupdate_state_metadata("Florida", counts_ok =counts_consistent(fl_clean),percentages_ok =percentages_consistent(fl_clean),notes_text ="Complete dataset provided. No processing or calculations required. All values are reported.")
Florida DNA Database Summary:
= ========================================
# A tibble: 1 × 3
offender_type value value_formatted
<chr> <dbl> <chr>
1 Combined 1175391 1,175,391
Data completeness:
# A tibble: 1 × 3
offender_type value_source n_values
<chr> <chr> <int>
1 Combined reported 22
Final verification:
Counts consistent: TRUE
Percentages consistent: TRUE
3.2.8 Summary of Florida Processing
Florida data processing complete. The dataset is exemplary and required no adjustments:
✅ Reported data: Both counts and percentages for all Convicted Offender, Arrestee, and Combined categories.
✅ Terminology standardization: “Caucasian” and “African American” converted to “White” and “Black”.
✅ No calculated additions needed: All values are sourced directly from the state report (value_source = "reported").
✅ Quality checks: All counts and percentages pass consistency validation.
✅ Provenance tracking: All values maintain their original value_source as “reported”.
The Florida data is now standardized and ready for cross-state analysis.
3.3 Indiana (IN)
Overview: Indiana presents a unique reporting pattern where total counts are provided by offender type, but demographic breakdowns are given only as percentages for the Combined total.
Values were provided as strings, including a “<1” notation, requiring conversion.
3.3.1 Examine Raw Data
Establish a baseline understanding of the data exactly as it was received.
Column
Type
Rows
Missing
Unique
Unique_Values
state
character
8
0
1
Indiana
offender_type
character
8
0
3
Convicted Offender, Arrestee, Combined
variable_category
character
8
0
3
total, gender, race
variable_detailed
character
8
0
7
total_profiles, Female, Male, Caucasian, Black, Hispanic, Other
value
numeric
8
0
8
279654, 21087, 20, 80, 70, 26, 4, 0.5
value_type
character
8
0
2
count, percentage
value_source
character
8
0
1
reported
Data frame dimensions: 8 rows × 7 columns
3.3.2 Verify Data Consistency
Initial checks reveal Indiana’s unique structure: counts for totals, percentages only for Combined demographics.
Initial data availability:
Race data: percentages
Gender data: percentages
Value types in raw data:
count, percentage
3.3.3 Address Data Gaps
3.3.3.1 Convert String Values to Numeric
The raw data contains string values including “<1” which we convert to 0.5.
Show value conversion code
# Start with raw datain_clean <- in_raw# Convert string values to numeric, handling "<1" as 1in_clean$value <-sapply(in_clean$value, function(x) {if (x =="<1") {0.5 } else {as.numeric(x) }})# Update value_type for converted percentagesin_clean <- in_clean %>%mutate(value_type =ifelse(value_type =="percentage", "percentage", value_type))cat("✓ Converted Indiana values from String to numeric\n")cat(paste("Unique values after conversion:", paste(unique(in_clean$value), collapse =", "), "\n"))
✓ Converted Indiana values from String to numeric
Unique values after conversion: 279654, 21087, 20, 80, 70, 26, 4, 0.5
3.3.3.2 Solve Percentages Inconsistency
Racial percentages summed to 100.5% instead of 100%
Proportional scaling was applied and value_source was updated to “calculated” for all adjusted values.
Show percentage recalculation code
# Adjust percentages to ensure they sum to 100% and mark as calculatedin_clean <- in_clean %>%group_by(value_type, variable_category) %>%mutate(value =ifelse( value_type =="percentage"& variable_category =="race", value * (100/sum(value, na.rm =TRUE)), value ),value_source =ifelse( value_type =="percentage"& variable_category =="race","calculated", value_source ) ) %>%ungroup()# Verify the new sumpercentage_sum <- in_clean %>%filter(value_type =="percentage"& variable_category =="race") %>%summarise(total =sum(value, na.rm =TRUE))cat("✓ Recalculated percentages for Indiana - New sum:", percentage_sum$total, "%\n")
✓ Recalculated percentages for Indiana - New sum: 100 %
Indiana provides separate totals for Convicted Offenders and Arrestees, but we need a Combined total to match the demographic percentages.
Show combined total calculation code
# Calculate Combined total from separate offender type totalsconvicted_total <- in_clean %>%filter(offender_type =="Convicted Offender", variable_category =="total", variable_detailed =="total_profiles") %>%pull(value)arrestee_total <- in_clean %>%filter(offender_type =="Arrestee", variable_category =="total", variable_detailed =="total_profiles") %>%pull(value)combined_total <- convicted_total + arrestee_total# Add Combined total to the datacombined_row <-data.frame(state ="Indiana",offender_type ="Combined",variable_category ="total",variable_detailed ="total_profiles",value = combined_total,value_type ="count",value_source ="calculated")in_clean <-bind_rows(in_clean, combined_row)cat(paste("Combined total profiles:", format(combined_total, big.mark =","), "\n"))cat("✓ Added Combined total profiles\n")
Combined total profiles: 300,741
✓ Added Combined total profiles
3.3.3.5 Calculate Counts from Percentages
Indiana only provides percentages for demographic categories. We calculate the actual counts using the Combined total.
Show count calculation code
# Calculate counts from percentages for Combined offender typein_clean <-bind_rows(in_clean, calculate_counts_from_percentages(in_clean, "Indiana"))cat("✓ Calculated demographic counts from percentages\n")# Verify the calculationscat("Category totals after calculating counts:\n")verify_category_totals(in_clean) %>%kable() %>%kable_styling()
✓ Calculated demographic counts from percentages
Category totals after calculating counts:
offender_type
variable_category
total_profiles
sum_counts
difference
Combined
gender
300741
300741
0
Combined
race
300741
300741
0
3.3.4 Verify Data Consistency
Final checks to ensure all data is now consistent and complete.
Final data consistency checks:
Counts consistent: TRUE
Percentages consistent: TRUE
Final data availability:
Race data: both
Gender data: both
3.3.5 Prepare for Combined Dataset
The cleaned data is formatted to match the master schema and appended to the foia_combined dataframe.
Show Indiana data preparation to combined dataset
# Prepare the cleaned data for the combined datasetin_prepared <-prepare_state_for_combined(in_clean, "Indiana")# Append to the master combined dataframefoia_combined <-bind_rows(foia_combined, in_prepared)cat(paste0("✓ Appended ", nrow(in_prepared), " Indiana rows to foia_combined\n"))cat(paste0("✓ Total rows in foia_combined: ", nrow(foia_combined), "\n"))
✓ Appended 15 Indiana rows to foia_combined
✓ Total rows in foia_combined: 88
3.3.6 Document Metadata
The metadata is added with details on all processing steps performed.
Show Indiana data preparation and addition to metadata table
# Add Indiana to the metadata table using the helper functionadd_state_metadata("Indiana", in_raw)# Update metadata with QC results and processing notesupdate_state_metadata("Indiana", counts_ok =counts_consistent(in_clean),percentages_ok =percentages_consistent(in_clean),notes_text ="Converted string values to numeric; standardized 'Black' to 'African American'; calculated Combined total profiles; derived all demographic counts from reported percentages")
cat("Indiana DNA Database Summary:\n")cat("=", strrep("=", 40), "\n")# Total profiles by offender typetotals <- foia_combined %>%filter(state =="Indiana", variable_category =="total", variable_detailed =="total_profiles", value_type =="count") %>%select(offender_type, value, value_source) %>%mutate(value_formatted =format(value, big.mark =","))print(totals)# Data completeness by value sourcecat("\nData completeness by source:\n")completeness <- foia_combined %>%filter(state =="Indiana") %>%group_by(value_source) %>%summarise(n_values =n(), .groups ="drop")print(completeness)# Final verificationcat("\nFinal verification:\n")cat(paste("Counts consistent:", counts_consistent(foia_combined %>%filter(state =="Indiana")), "\n"))cat(paste("Percentages consistent:", percentages_consistent(foia_combined %>%filter(state =="Indiana")), "\n"))
Indiana DNA Database Summary:
= ========================================
# A tibble: 3 × 4
offender_type value value_source value_formatted
<chr> <dbl> <chr> <chr>
1 Convicted Offender 279654 reported "279,654"
2 Arrestee 21087 reported " 21,087"
3 Combined 300741 calculated "300,741"
Data completeness by source:
# A tibble: 2 × 2
value_source n_values
<chr> <int>
1 calculated 11
2 reported 4
Final verification:
Counts consistent: TRUE
Percentages consistent: TRUE
3.3.9 Summary of Indiana Processing
Indiana data processing complete. The unique dataset required:
✅ Data conversion: String values converted to numeric, handling “<1” as 0.5
✅ Terminology standardization: “Caucasian” converted to “White”
✅ Calculated additions:
Combined total profiles across offender types
All demographic counts derived from reported percentages
✅ Quality checks: All counts and percentages pass consistency validation
✅ Provenance tracking: Clear distinction between reported and calculated values
The Indiana data is now standardized and ready for cross-state analysis.
3.4 Maine (ME)
Overview: Maine provides comprehensive reporting with both counts and percentages for all gender and race categories across all offender types, including pre-calculated Combined totals. The data is complete and requires no processing.
3.4.1 Examine Raw Data
Establish a baseline understanding of the data exactly as it was received.
Column
Type
Rows
Missing
Unique
Unique_Values
state
character
19
0
1
Maine
offender_type
character
19
0
1
Combined
variable_category
character
19
0
3
total, gender, race
variable_detailed
character
19
0
9
total_profiles, Male, Female, Unknown, White, Black, Native American, Hispanic, Asian
Runs quality checks using the verify_category_totals(), counts_consistent(), and percentages_consistent() functions.
Verifying that demographic counts match reported totals:
offender_type
variable_category
total_profiles
sum_counts
difference
Combined
gender
33711
33511
200
Combined
race
33711
33711
0
Counts consistency check on raw data:
All counts consistent: FALSE
Percentage consistency check on raw data:
All percentages sum to ~100%: TRUE
3.4.3 Address Data Gaps
3.4.3.1 Solve Percentages Inconsistency
Racial percentages summed to 99.9% instead of 100%
Proportional scaling was applied and value_source was updated to “calculated” for all adjusted values.
Show percentage recalculation code
# Start with the raw datame_clean <- me_raw# Adjust percentages to ensure they sum to 100% and mark as calculatedme_clean <- me_clean %>%group_by(value_type, variable_category) %>%mutate(value =ifelse( value_type =="percentage"& variable_category =="gender", value * (100/sum(value, na.rm =TRUE)), value ),value_source =ifelse( value_type =="percentage"& variable_category =="gender","calculated", value_source ) ) %>%ungroup()# Verify the new sumpercentage_sum <- me_clean %>%filter(value_type =="percentage"& variable_category =="gender") %>%summarise(total =sum(value, na.rm =TRUE))cat("✓ Recalculated percentages for Maine - New sum:", round(percentage_sum$total, 2), "%\n")
✓ Recalculated percentages for Maine - New sum: 100 %
3.4.3.2 Recalculate Counts from Percentages
Maine’s reported gender counts sum were inconsistent with the total_profiles.
We removed existing gender count data and recalculated counts using percentage values and combined totals.
All recalculated values flagged with value_source = "calculated"
Show count recalculation code
# Remove existing gender count rows to avoid duplicationme_clean <- me_clean %>%filter(!(variable_category =="gender"& value_type =="count"))cat("✓ Removed existing gender count data\n")me_gender <- me_clean %>%filter(variable_category =="gender"| variable_category =="total")# Calculate counts from percentages for Combined offender typeme_gender <-calculate_counts_from_percentages(me_gender, "Maine")# Append recalculated gender counts to the main datasetme_clean <-bind_rows(me_clean, me_gender)cat("✓ Calculated demographic counts from percentages\n")# Verify the calculationscat("Category totals after calculating counts:\n")verify_category_totals(me_clean) %>%kable() %>%kable_styling()
✓ Removed existing gender count data
✓ Calculated demographic counts from percentages
Category totals after calculating counts:
offender_type
variable_category
total_profiles
sum_counts
difference
Combined
gender
33711
33711
0
Combined
race
33711
33711
0
3.4.4 Verify Data Consistency
Final checks to ensure all data is now consistent and complete.
Final data consistency checks:
Counts consistent: TRUE
Percentages consistent: TRUE
Final data availability:
Race data: both
Gender data: both
3.4.5 Prepare for Combined Dataset
The Maine data is already complete and consistent. It is formatted to match the master schema and appended to the foia_combined dataframe.
Show Maine data preparation to combined dataset
# Prepare the data for the combined datasetme_prepared <-prepare_state_for_combined(me_clean, "Maine")# Append to the master combined dataframefoia_combined <-bind_rows(foia_combined, me_prepared)cat(paste0("✓ Appended ", nrow(me_prepared), " Maine rows to foia_combined\n"))cat(paste0("✓ Total rows in foia_combined: ", nrow(foia_combined), "\n"))
✓ Appended 19 Maine rows to foia_combined
✓ Total rows in foia_combined: 107
3.4.6 Document Metadata
The metadata is added with a note that the data was complete and required no processing.
Show Maine data preparation and addition to metadata table
# Add Maine to the metadata table using the helper functionadd_state_metadata("Maine", me_raw)# Update metadata with QC resultsupdate_state_metadata("Maine", counts_ok =counts_consistent(me_clean),percentages_ok =percentages_consistent(me_clean),notes_text ="Complete dataset provided with both counts and percentages. No processing or calculations required. All values are reported.")
✓ Metadata added for: Maine
✓ Metadata updated for: Maine
Maine DNA Database Summary:
= ========================================
# A tibble: 1 × 3
offender_type value value_formatted
<chr> <dbl> <chr>
1 Combined 33711 33,711
Data completeness:
# A tibble: 2 × 3
offender_type value_source n_values
<chr> <chr> <int>
1 Combined calculated 6
2 Combined reported 13
Final verification:
Counts consistent: TRUE
Percentages consistent: TRUE
3.4.9 Summary of Maine Processing
Maine data processing complete. The dataset is exemplary and required no adjustments:
✅ Reported data: Both counts and percentages for all Convicted Offender, Arrestee, and Combined categories
✅ No calculated additions needed: All values are sourced directly from the state report (value_source = "reported")
✅ Quality checks: All counts and percentages pass consistency validation
✅ Provenance tracking: All values maintain their original value_source as “reported”
The Maine data is now standardized and ready for cross-state analysis.
3.5 Nevada (NV)
Overview: Nevada provides both counts and percentages for gender and race categories but uses non-standard terminology that requires conversion for consistency with our schema.
3.5.1 Examine Raw Data
Establish a baseline understanding of the data exactly as it was received.
Column
Type
Rows
Missing
Unique
Unique_Values
state
character
21
0
1
Nevada
offender_type
character
21
0
4
All, Arrestee, Convicted Offender, Combined
variable_category
character
21
0
3
total, gender, race
variable_detailed
character
21
0
9
total_flags, total_profiles, Female, Male, Unknown, White, American Indian, Black, Asian
Now that the offender types are standardized, we can verify the counts and percentages.
Verifying that demographic counts match reported totals:
offender_type
variable_category
total_profiles
sum_counts
difference
Combined
gender
344097
344097
0
Combined
race
344097
344097
0
Counts consistency check on raw data:
All counts consistent: TRUE
Percentage consistency check on raw data:
All percentages sum to ~100%: TRUE
Sum of 'race' percentages: 100 %
Sum of 'gender' percentages: 100 %
3.5.4 Prepare for Combined Dataset
The cleaned data is formatted to match the master schema and appended to the foia_combined dataframe.
Show Nevada data preparation to combined dataset
# Prepare the cleaned data for the combined datasetnv_prepared <-prepare_state_for_combined(nv_clean, "Nevada")# Append to the master combined dataframefoia_combined <-bind_rows(foia_combined, nv_prepared)cat(paste0("✓ Appended ", nrow(nv_prepared), " Nevada rows to foia_combined\n"))cat(paste0("✓ Total rows in foia_combined: ", nrow(foia_combined), "\n"))
✓ Appended 21 Nevada rows to foia_combined
✓ Total rows in foia_combined: 128
3.5.5 Document Metadata
The metadata is added with details on the terminology standardization performed.
Show Nevada data preparation and addition to metadata table
# Add Nevada to the metadata table using the helper functionadd_state_metadata("Nevada", nv_raw)# Update metadata with QC results and processing notesupdate_state_metadata("Nevada", counts_ok =counts_consistent(nv_clean),percentages_ok =percentages_consistent(nv_clean),notes_text ="Standardized terminology: 'All' to 'Combined' and 'American Indian' to 'Native American'. All values remain reported.")
✅ Reported data: Both counts and percentages for all categories
✅ Quality checks: All counts and percentages pass consistency validation
✅ Provenance tracking: All values maintain value_source = "reported" as only terminology changes were made
The Nevada data is now standardized and ready for cross-state analysis.
3.6 South Dakota (SD)
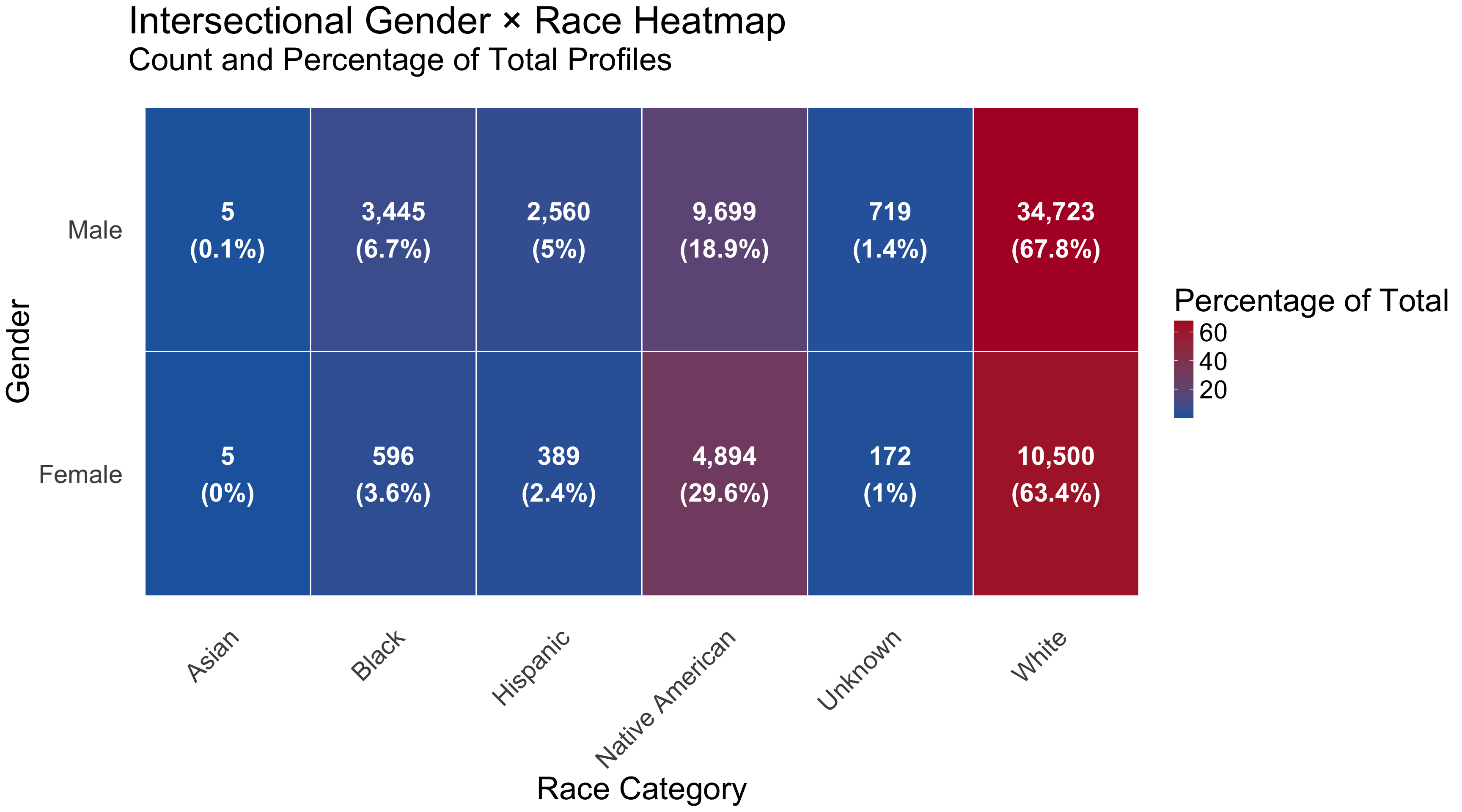
Overview: South Dakota provides the most comprehensive reporting with both counts and percentages for all standard categories plus unique intersectional gender×race data. Minor terminology standardization is required for consistency.
3.6.1 Examine Raw Data
Establish a baseline understanding of the data exactly as it was received.
Column
Type
Rows
Missing
Unique
Unique_Values
state
character
41
0
1
South Dakota
offender_type
character
41
0
1
Combined
variable_category
character
41
0
4
total, gender, race, gender_race
variable_detailed
character
41
0
21
total_profiles ..., Male ..., Female ..., Asian ..., Black ..., Hispanic ..., Native American ..., Other/Unknown ..., White/Caucasian ..., Male_Asian ...
South Dakota’s reported race counts sum were inconsistent with the total_profiles.
We removed existing gender count data and recalculated counts using percentage values and combined totals.
All recalculated values flagged with value_source = "calculated"
Show count recalculation code
# Remove existing gender count rows to avoid duplicationsd_clean <- sd_clean %>%filter(!(variable_category =="race"& value_type =="count"))cat("✓ Removed existing race count data\n")sd_race <- sd_clean %>%filter(variable_category =="race"| variable_category =="total")# Calculate counts from percentages for Combined offender typesd_race <-calculate_counts_from_percentages(sd_race, "South Dakota")# Append recalculated race counts to the main datasetsd_clean <-bind_rows(sd_clean, sd_race)cat("✓ Calculated demographic counts from percentages\n")# Verify the calculationscat("Category totals after calculating counts:\n")verify_category_totals(sd_clean) %>%kable() %>%kable_styling()
✓ Removed existing race count data
✓ Calculated demographic counts from percentages
Category totals after calculating counts:
offender_type
variable_category
total_profiles
sum_counts
difference
Combined
gender
67753
67753
0
Combined
race
67753
67752
1
We handled this diffence of 1 by adding it to the most representative race (White).
Show difference handle code
# Handle the difference of 1 by adding it to the most representative racesd_clean <- sd_clean %>%mutate(value =ifelse(variable_detailed =="White"& value_type =="count", value +1, value))
3.6.5 Verify Data Consistency
Final checks to ensure standardization didn’t affect data integrity.
Final data consistency checks after standardization:
Verifying that demographic counts match reported totals:
offender_type
variable_category
total_profiles
sum_counts
difference
Combined
gender
67753
67753
0
Combined
race
67753
67753
0
Counts consistency check:
All counts consistent: TRUE
Percentage consistency check:
All percentages sum to ~100%: TRUE
3.6.6 Prepare for Combined Dataset
The cleaned data is formatted to match the master schema and appended to the foia_combined dataframe.
Show South Dakota data preparation to combined dataset
# Prepare the cleaned data for the combined datasetsd_prepared <-prepare_state_for_combined(sd_clean, "South Dakota")# Append to the master combined dataframefoia_combined <-bind_rows(foia_combined, sd_prepared)cat(paste0("✓ Appended ", nrow(sd_prepared), " South Dakota rows to foia_combined\n"))cat(paste0("✓ Total rows in foia_combined: ", nrow(foia_combined), "\n"))# Show the comprehensive nature of South Dakota's datacat("\nSouth Dakota's comprehensive data structure:\n")sd_prepared %>%group_by(variable_category) %>%summarise(n_rows =n(), .groups ="drop") %>%kable() %>%kable_styling()
✓ Appended 17 South Dakota rows to foia_combined
✓ Total rows in foia_combined: 145
South Dakota's comprehensive data structure:
variable_category
n_rows
gender
4
race
12
total
1
3.6.7 Document Metadata
The metadata is added with details on South Dakota’s comprehensive reporting and the terminology standardization performed.
Show South Dakota data preparation and addition to metadata table
# Add South Dakota to the metadata table using the helper functionadd_state_metadata("South Dakota", sd_raw)# Update metadata with QC results and processing notesupdate_state_metadata("South Dakota", counts_ok =counts_consistent(sd_clean),percentages_ok =percentages_consistent(sd_clean),notes_text ="Standardized terminology: 'White/Caucasian' to 'White' and 'Other/Unknown' to 'Unknown'. Includes comprehensive gender_race intersectional data. All values remain reported.")
✓ Metadata added for: South Dakota
✓ Metadata updated for: South Dakota
3.6.8 Visualizations
South Dakota DNA Database Demographic Distributions
South Dakota DNA Database Demographic Distributions
South Dakota DNA Database Demographic Distributions
South Dakota DNA Database Demographic Distributions
3.6.9 Summary Statistics
Show the summary statistics code
cat("South Dakota DNA Database Summary:\n")cat("=", strrep("=", 40), "\n")# Total profiles by offender typetotals <- foia_combined %>%filter(state =="South Dakota", variable_category =="total", variable_detailed =="total_profiles", value_type =="count") %>%select(offender_type, value) %>%mutate(value_formatted =format(value, big.mark =","))print(totals)# Data completeness by categorycat("\nData completeness by category:\n")completeness <- foia_combined %>%filter(state =="South Dakota") %>%group_by(variable_category) %>%summarise(n_values =n(), .groups ="drop")print(completeness)# Final verificationcat("\nFinal verification:\n")cat(paste("Counts consistent:", counts_consistent(foia_combined %>%filter(state =="South Dakota")), "\n"))cat(paste("Percentages consistent:", percentages_consistent(foia_combined %>%filter(state =="South Dakota")), "\n"))
South Dakota DNA Database Summary:
= ========================================
# A tibble: 1 × 3
offender_type value value_formatted
<chr> <dbl> <chr>
1 Combined 67753 67,753
Data completeness by category:
# A tibble: 3 × 2
variable_category n_values
<chr> <int>
1 gender 4
2 race 12
3 total 1
Final verification:
Counts consistent: TRUE
Percentages consistent: TRUE
3.6.10 Summary of South Dakota Processing
South Dakota data processing complete. The state provided exemplary data with minimal adjustments needed:
✅ Terminology standardization:
“White/Caucasian” → “White”
“Other/Unknown” → “Unknown”
✅ Comprehensive reporting: Standard demographics plus unique gender×race intersectional data
✅ Reported data: Both counts and percentages for all categories
✅ Quality checks: All counts and percentages pass consistency validation
✅ Provenance tracking: All values maintain value_source = "reported" as only terminology changes were made
South Dakota’s data is now standardized and ready for cross-state analysis.
3.7 Texas (TX)
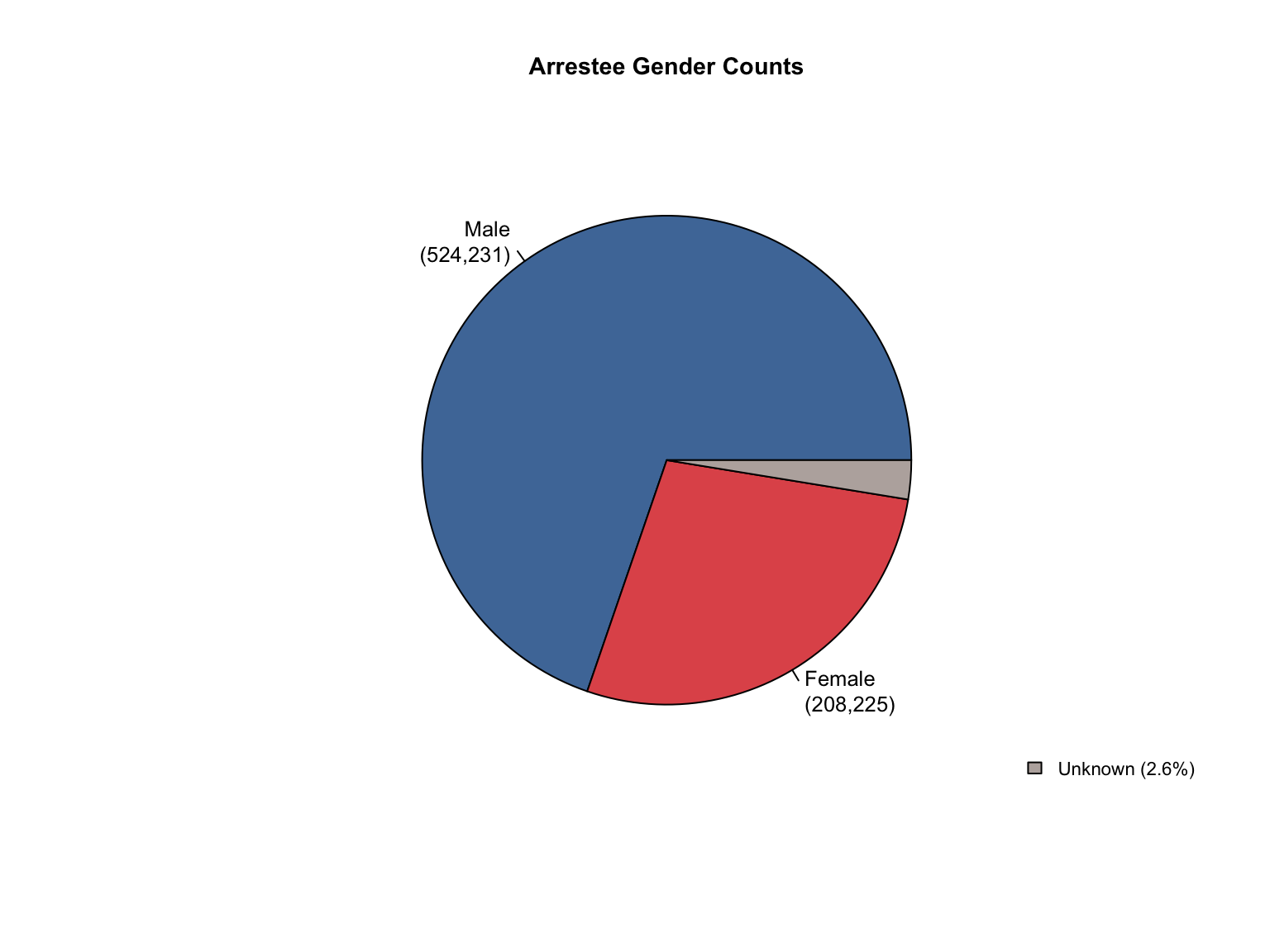
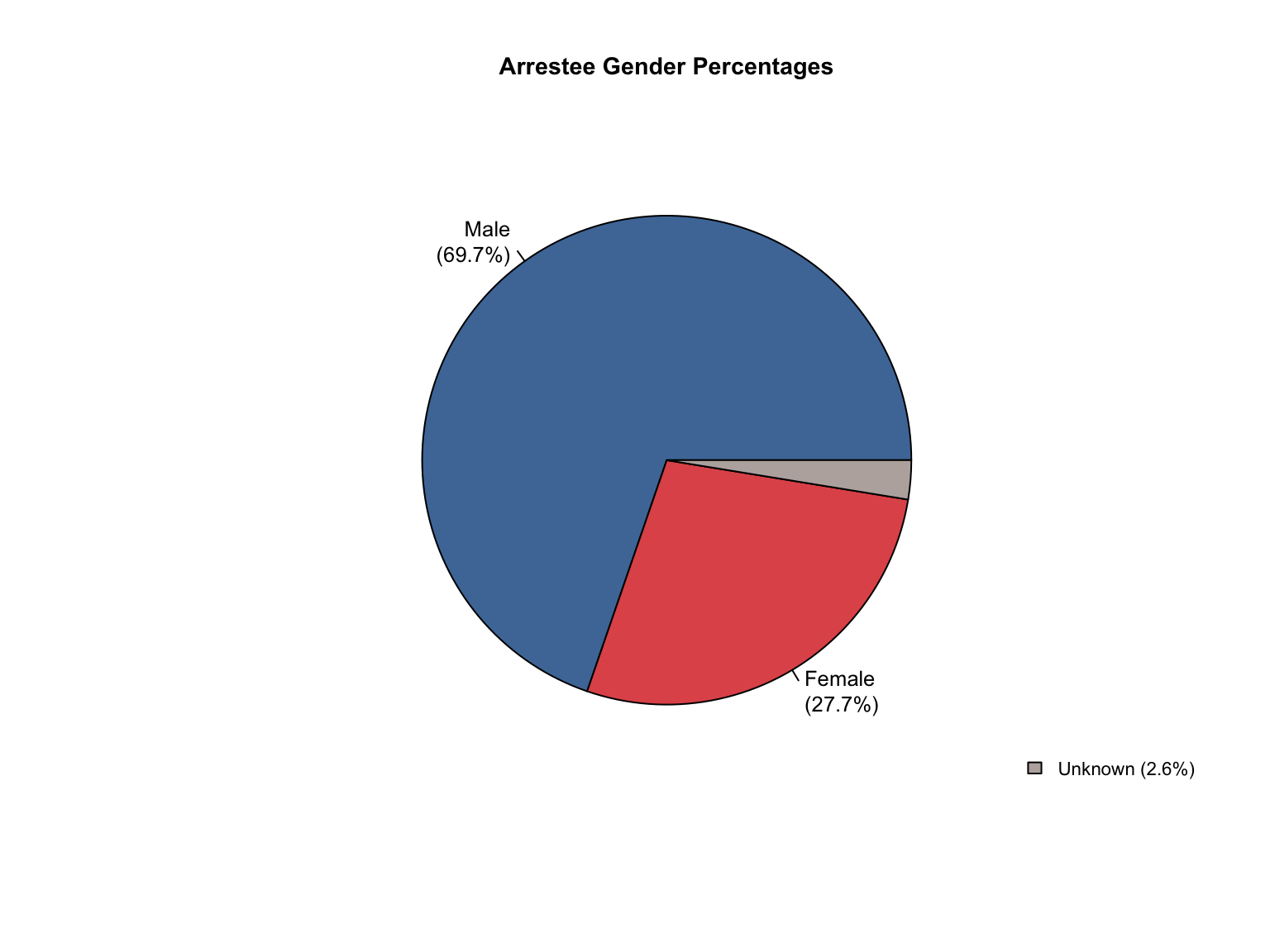
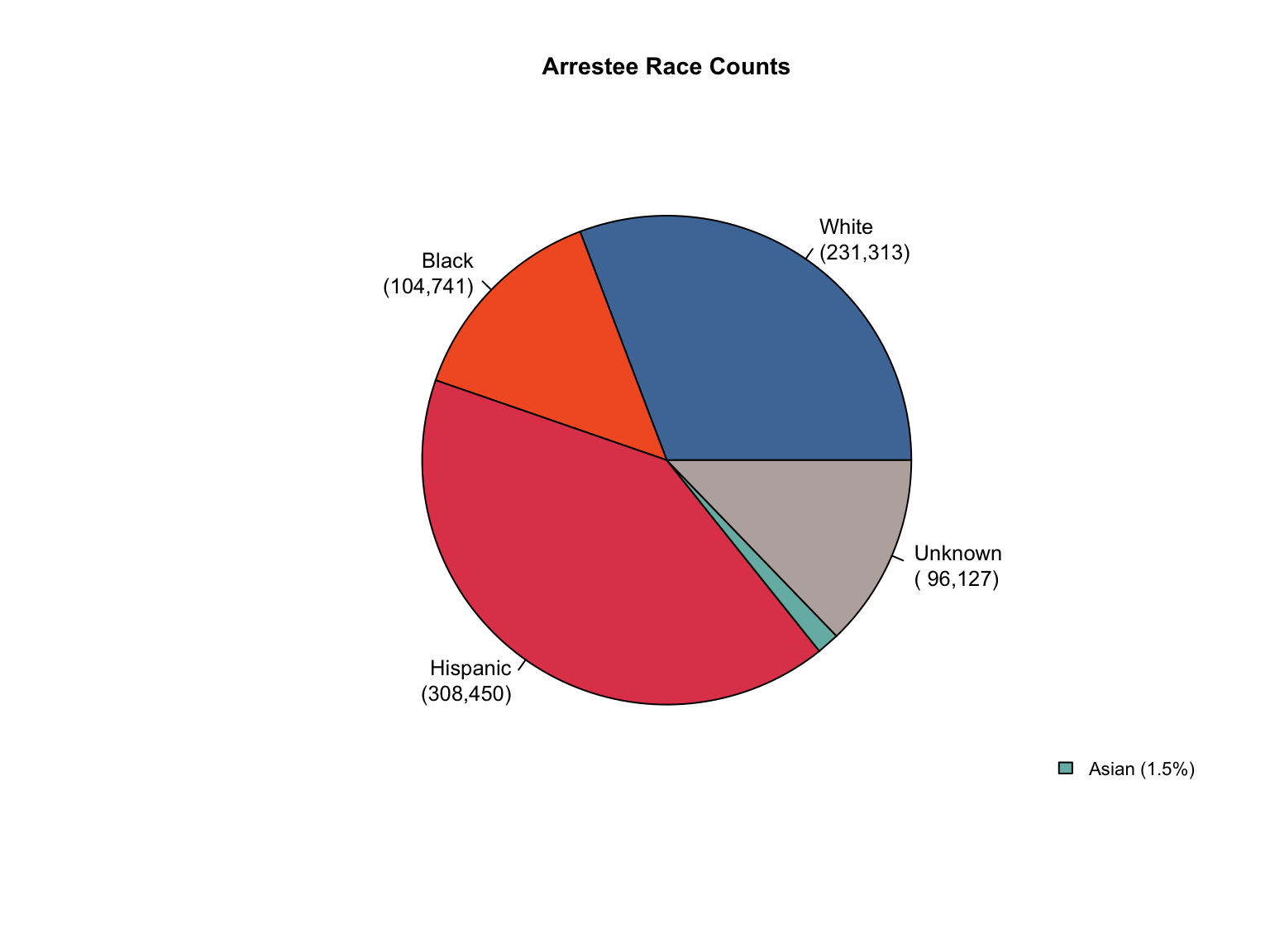
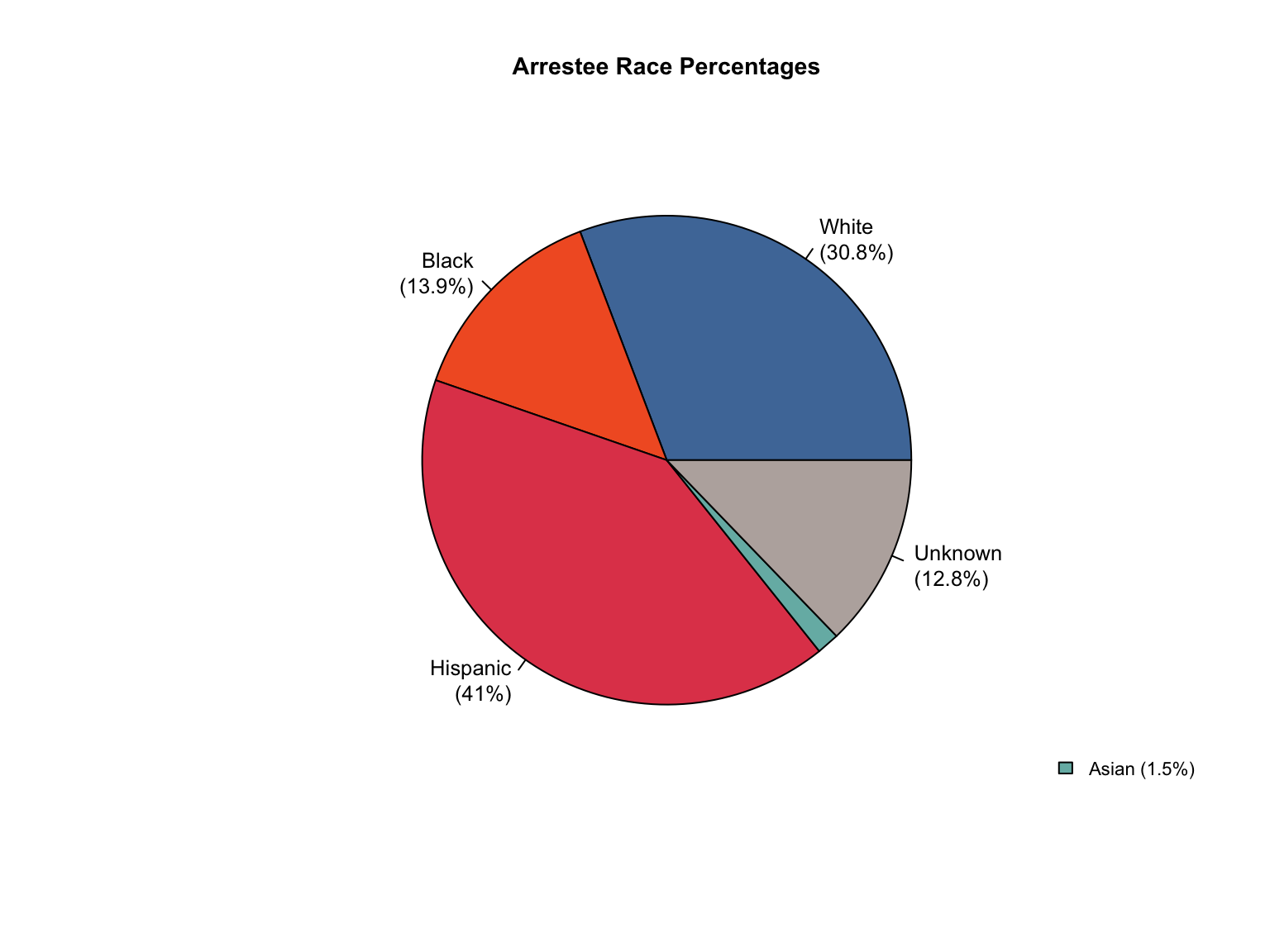
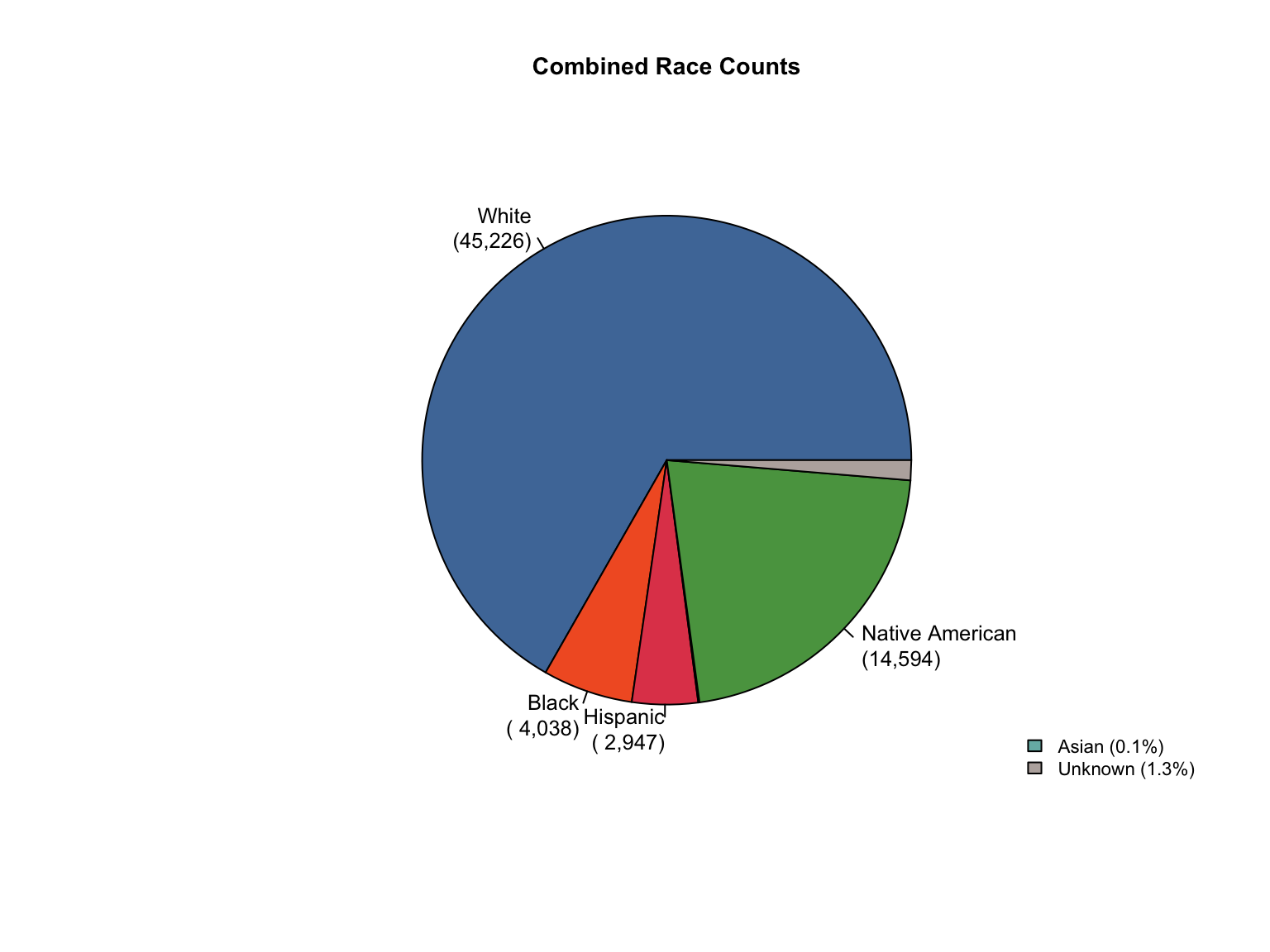
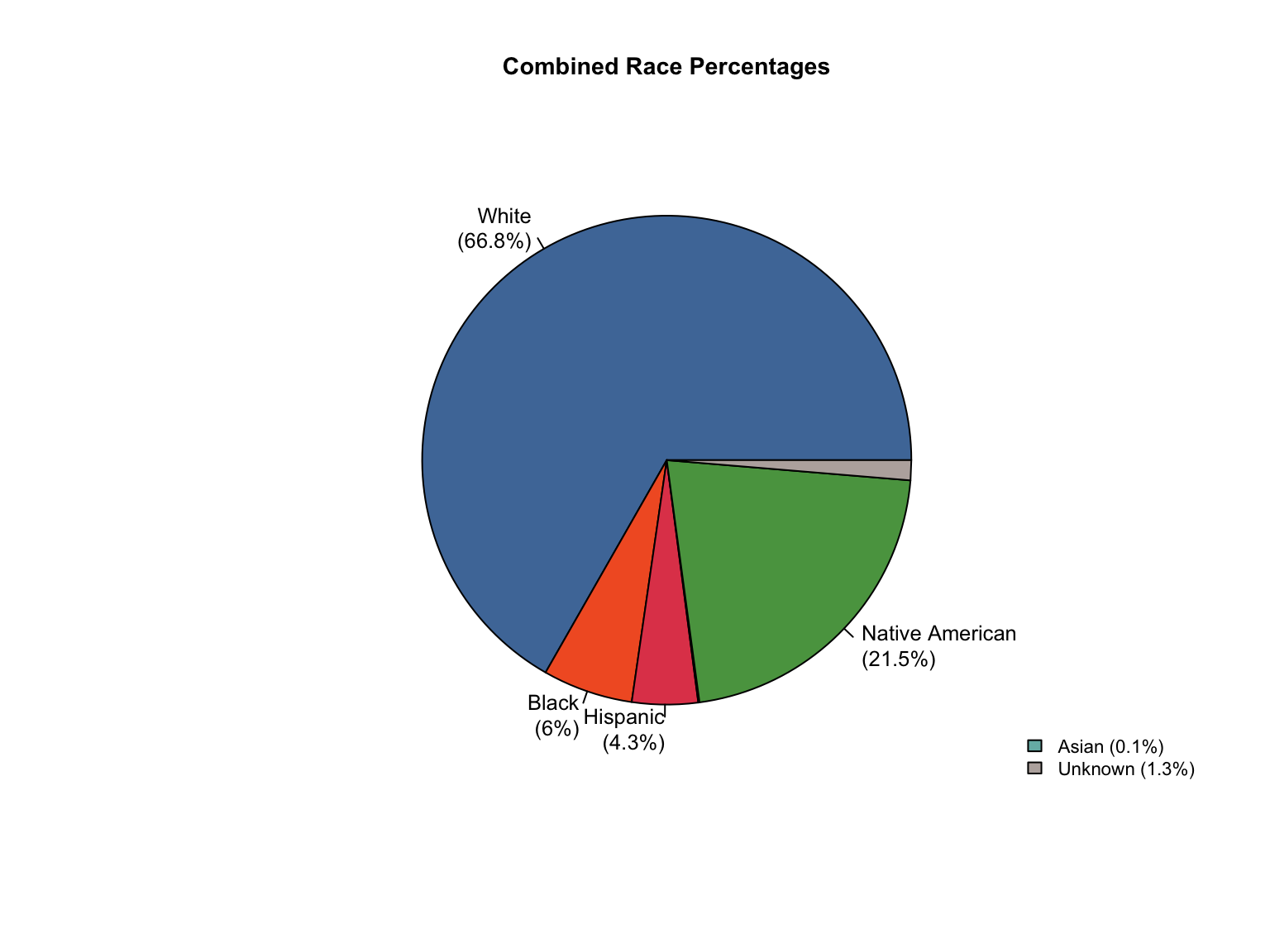
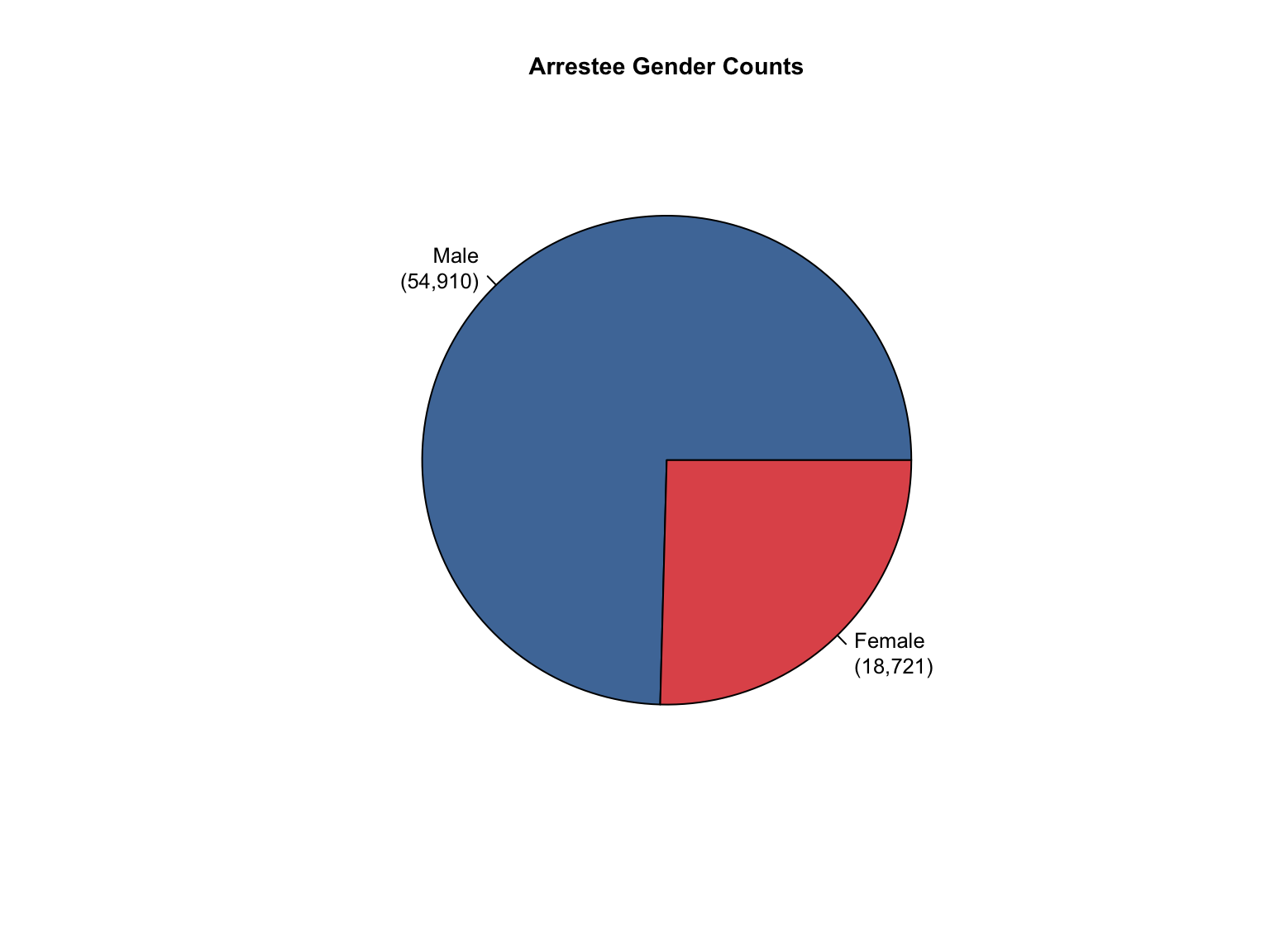
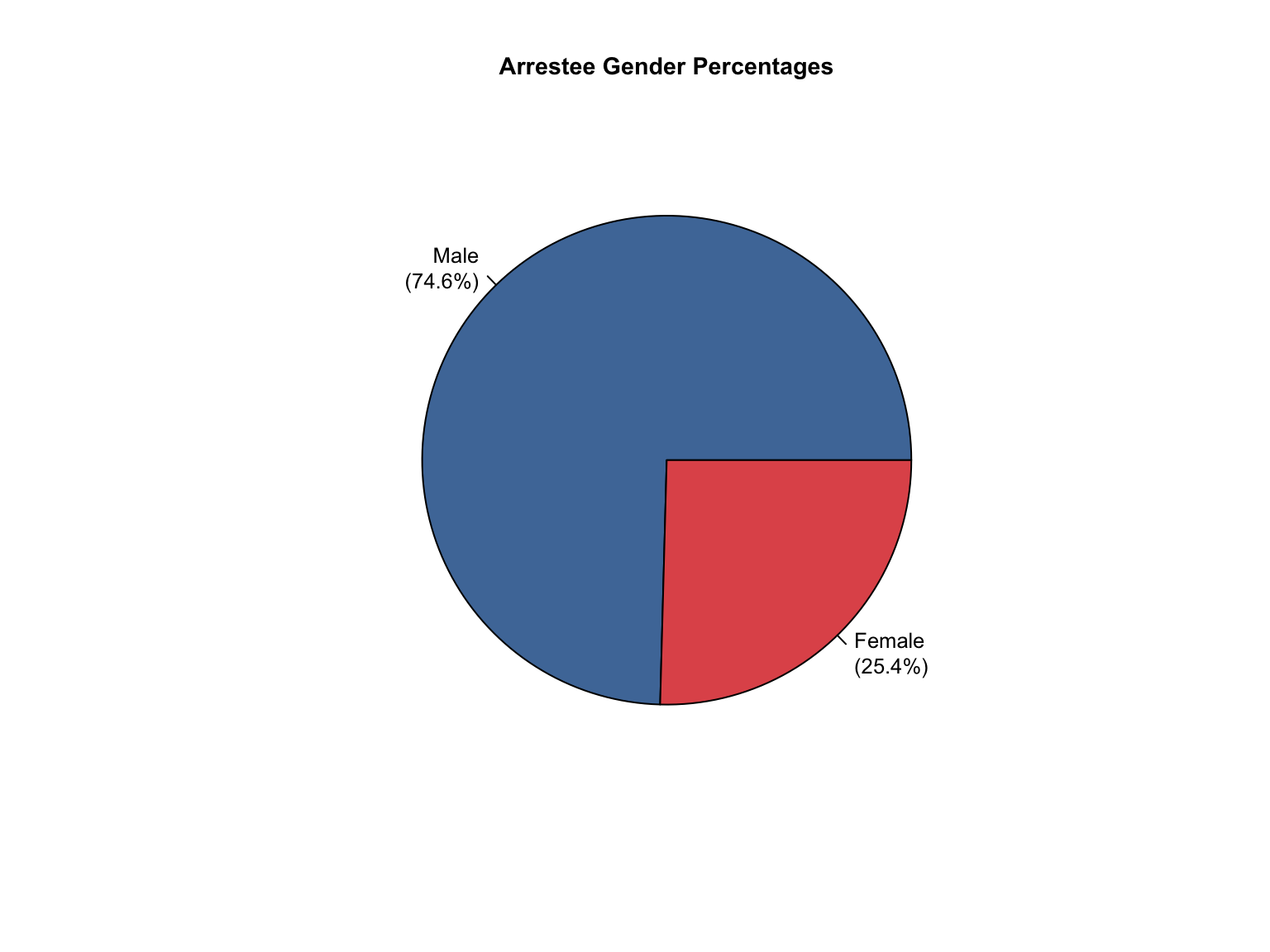
Overview: Texas provides counts only for gender and race categories. The Male gender is missing in the dataset. The state uses non-standard terminology that requires conversion and needs Combined totals and percentages calculated.
3.7.1 Examine Raw Data
Establish a baseline understanding of the data exactly as it was received.
Column
Type
Rows
Missing
Unique
Unique_Values
state
character
16
0
1
Texas
offender_type
character
16
0
2
Offenders, Arrestee
variable_category
character
16
0
3
total, gender, race
variable_detailed
character
16
0
8
total_profiles, Female, Asian, African American, Caucasian, Hispanic, Native American, Other
Initial checks reveal Texas’s reporting structure and terminology differences.
Initial data availability:
Race data: counts
Gender data: counts
Non-standard terminology found:
Offender types: Offenders, Arrestee
Race terms: Asian, African American, Caucasian, Hispanic, Native American, Other
3.7.3 Address Data Gaps
3.7.3.1 Add Missing Male category
Texas data reports only Female counts explicitly. We calculated Male counts by subtracting Female counts from total profiles, assuming binary gender classification in the dataset.
Show male addition code
# First, let's examine the current structure of gender datagender_data <- tx_raw %>%filter(variable_category =="gender")cat("Current gender structure:\n")print(unique(gender_data$variable_detailed))# Get total profiles for each offender typetotal_profiles <- tx_raw %>%filter(variable_category =="total"& variable_detailed =="total_profiles") %>%select(offender_type, total_value = value)# Join total profiles with gender datagender_with_totals <- gender_data %>%left_join(total_profiles, by ="offender_type")# Create Male entries for each offender typemale_entries <- gender_with_totals %>%filter(variable_detailed =="Female") %>%mutate(variable_detailed ="Male",value = total_value - value, value_source ="calculated",total_value =NULL )# Add these entries to the original datasettx_raw_with_male <- tx_raw %>%bind_rows(male_entries)# Update the tx_raw objecttx_clean <- tx_raw_with_male# Verify the additioncat("\nAfter adding Male entries - gender categories:\n")print(unique(tx_clean %>%filter(variable_category =="gender") %>%pull(variable_detailed)))
Current gender structure:
[1] "Female"
After adding Male entries - gender categories:
[1] "Female" "Male"
3.7.3.2 Standardize Terminology
Texas uses “Offenders” instead of “Convicted Offender” and “Caucasian” instead of “White”.
Texas race count is inconsistent, with a significant number of profiles not reported in any racial category.
Unknown category was created to account for these missing profiles.
The calculated values are added with a value_source = "calculated" tag to maintain transparency about what was provided versus what was derived.
Show unknown addition code
# Add Unknown race category to reconcile totalstx_clean <-fill_demographic_gaps(tx_clean)# Verify the fixcat("Category totals after adding Unknown race category:\n")verify_category_totals(tx_clean) %>%kable() %>%kable_styling()cat("\nCounts consistency after adding Unknown:\n")cat(paste("All counts consistent:", counts_consistent(tx_clean), "\n"))
Category totals after adding Unknown race category:
offender_type
variable_category
total_profiles
sum_counts
difference
Arrestee
gender
73631
73631
0
Arrestee
race
73631
73631
0
Convicted Offender
gender
845322
845322
0
Convicted Offender
race
845322
845322
0
Counts consistency after adding Unknown:
All counts consistent: TRUE
3.7.3.4 Create Combined Totals
Texas only reported data for “Convicted Offender” and “Arrestee” separately. We calculate Combined totals.
Show combined addition code
# Calculate Combined totals using helper functiontx_clean <-add_combined(tx_clean)cat("✓ Created Combined totals for Texas\n")# Show the Combined totalcombined_total <- tx_clean %>%filter(offender_type =="Combined", variable_category =="total", variable_detailed =="total_profiles") %>%pull(value)cat(paste("Combined total profiles:", format(combined_total, big.mark =","), "\n"))
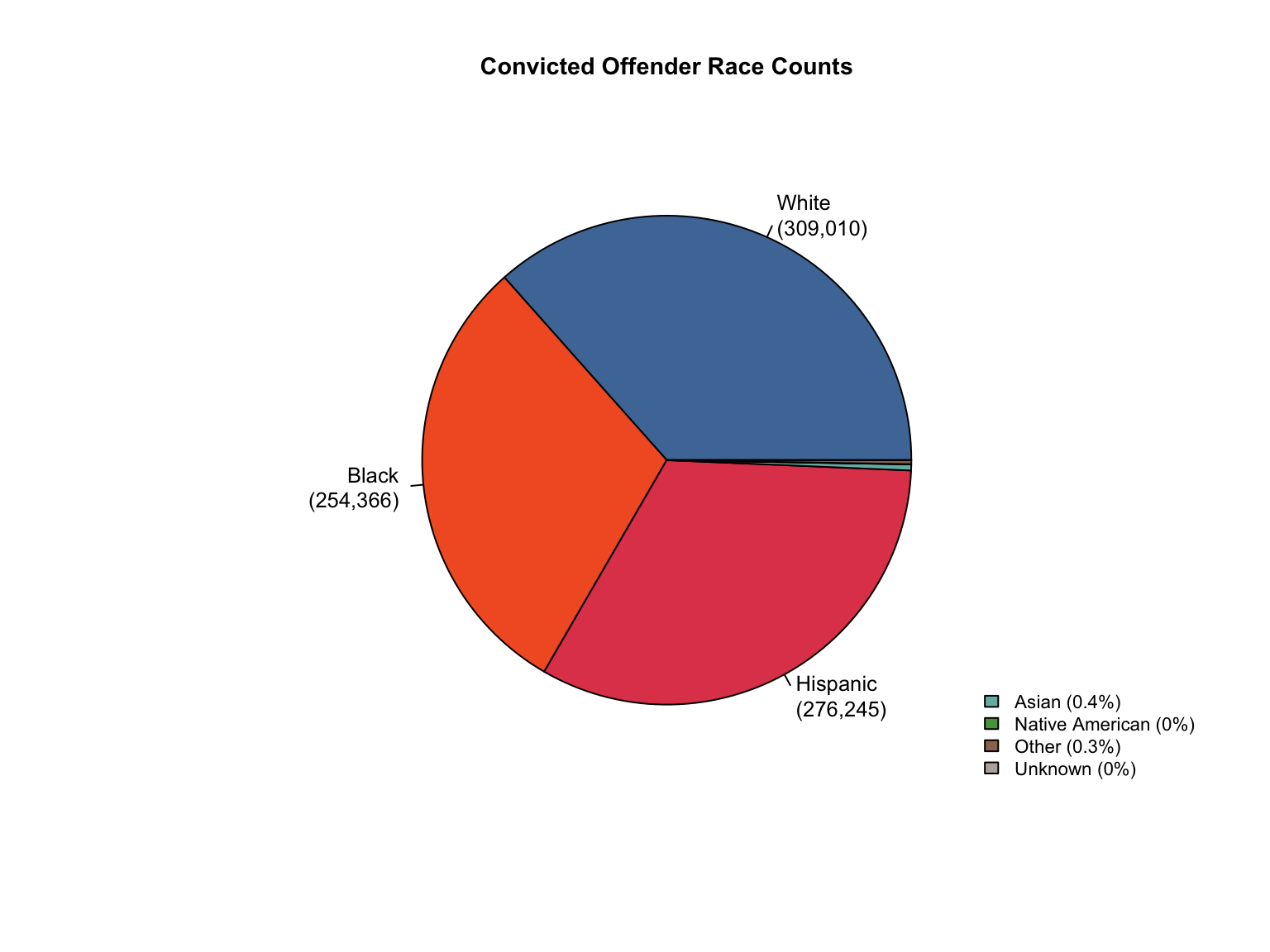
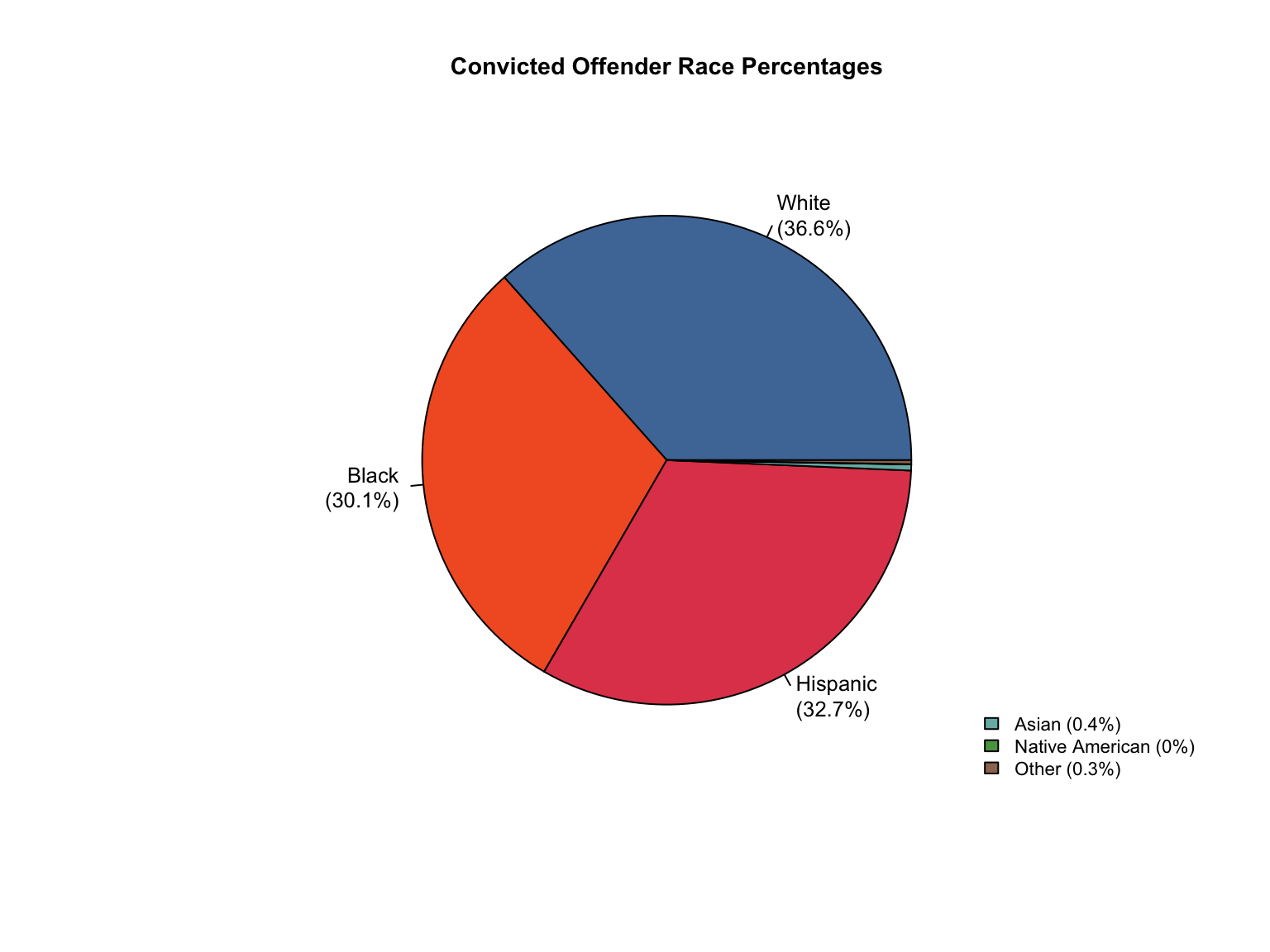
✓ Created Combined totals for Texas
Combined total profiles: 918,953
3.7.3.5 Calculate Percentages
Transforms the data from counts into percentages for comparative analysis.
Show percentage calculation code
# Derive percentages from countstx_clean <-add_percentages(tx_clean)cat("✓ Added percentages for all demographic categories\n")# Check percentage consistencycat("Percentage consistency check:\n")cat(paste("All percentages sum to ~100%:", percentages_consistent(tx_clean), "\n\n"))# Show current data availabilitycat("Final data availability:\n")cat(paste("Race data:", report_status(tx_clean, "race"), "\n"))cat(paste("Gender data:", report_status(tx_clean, "gender"), "\n"))
✓ Added percentages for all demographic categories
Percentage consistency check:
All percentages sum to ~100%: TRUE
Final data availability:
Race data: both
Gender data: both
3.7.4 Verify Data Consistency
Final checks to ensure all processing maintained data integrity.
Final data consistency checks:
Verifying that demographic counts match reported totals:
offender_type
variable_category
total_profiles
sum_counts
difference
Arrestee
gender
73631
73631
0
Arrestee
race
73631
73631
0
Combined
gender
918953
918953
0
Combined
race
918953
918953
0
Convicted Offender
gender
845322
845322
0
Convicted Offender
race
845322
845322
0
Counts consistency check:
All counts consistent: TRUE
Percentage consistency check:
All percentages sum to ~100%: TRUE
3.7.5 Prepare for Combined Dataset
The cleaned data is formatted to match the master schema and appended to the foia_combined dataframe.
Show Texas data preparation to combined dataset
# Prepare the cleaned data for the combined datasettx_prepared <-prepare_state_for_combined(tx_clean, "Texas")# Append to the master combined dataframefoia_combined <-bind_rows(foia_combined, tx_prepared)cat(paste0("✓ Appended ", nrow(tx_prepared), " Texas rows to foia_combined\n"))cat(paste0("✓ Total rows in foia_combined: ", nrow(foia_combined), "\n"))
✓ Appended 57 Texas rows to foia_combined
✓ Total rows in foia_combined: 202
3.7.6 Document Metadata
The metadata is added with details on all processing steps performed.
Show Texas data preparation and addition to metadata table
# Add Texas to the metadata table using the helper functionadd_state_metadata("Texas", tx_raw)# Update metadata with QC results and processing notesupdate_state_metadata("Texas", counts_ok =counts_consistent(tx_clean),percentages_ok =percentages_consistent(tx_clean),notes_text ="Standardized terminology: 'Offenders' to 'Convicted Offender', 'Caucasian' to 'White', 'African American' to 'Black'; calculated Combined totals and all percentages")
cat("Texas DNA Database Summary:\n")cat("=", strrep("=", 40), "\n")# Total profiles by offender typetotals <- foia_combined %>%filter(state =="Texas", variable_category =="total", variable_detailed =="total_profiles", value_type =="count") %>%select(offender_type, value, value_source) %>%mutate(value_formatted =format(value, big.mark =","))print(totals)# Data completeness by value sourcecat("\nData completeness by source:\n")completeness <- foia_combined %>%filter(state =="Texas") %>%group_by(value_source) %>%summarise(n_values =n(), .groups ="drop")print(completeness)# Final verificationcat("\nFinal verification:\n")cat(paste("Counts consistent:", counts_consistent(foia_combined %>%filter(state =="Texas")), "\n"))cat(paste("Percentages consistent:", percentages_consistent(foia_combined %>%filter(state =="Texas")), "\n"))
Texas DNA Database Summary:
= ========================================
# A tibble: 3 × 4
offender_type value value_source value_formatted
<chr> <dbl> <chr> <chr>
1 Convicted Offender 845322 reported "845,322"
2 Arrestee 73631 reported " 73,631"
3 Combined 918953 calculated "918,953"
Data completeness by source:
# A tibble: 2 × 2
value_source n_values
<chr> <int>
1 calculated 41
2 reported 16
Final verification:
Counts consistent: TRUE
Percentages consistent: TRUE
3.7.9 Summary of Texas Processing
Texas data processing complete. The dataset required several adjustments:
✅ Male Category Addition:
“Male” added to variable_detailed
✅ Terminology standardization:
“Offenders” → “Convicted Offender”
“Caucasian” → “White”
“African American” → “Black”
✅ Calculated additions:
Combined totals across all offender types
Percentage values for all demographic categories
✅ Quality checks: All counts and percentages pass consistency validation
✅ Provenance tracking: Clear distinction between reported and calculated values
The Texas data is now standardized and ready for cross-state analysis.
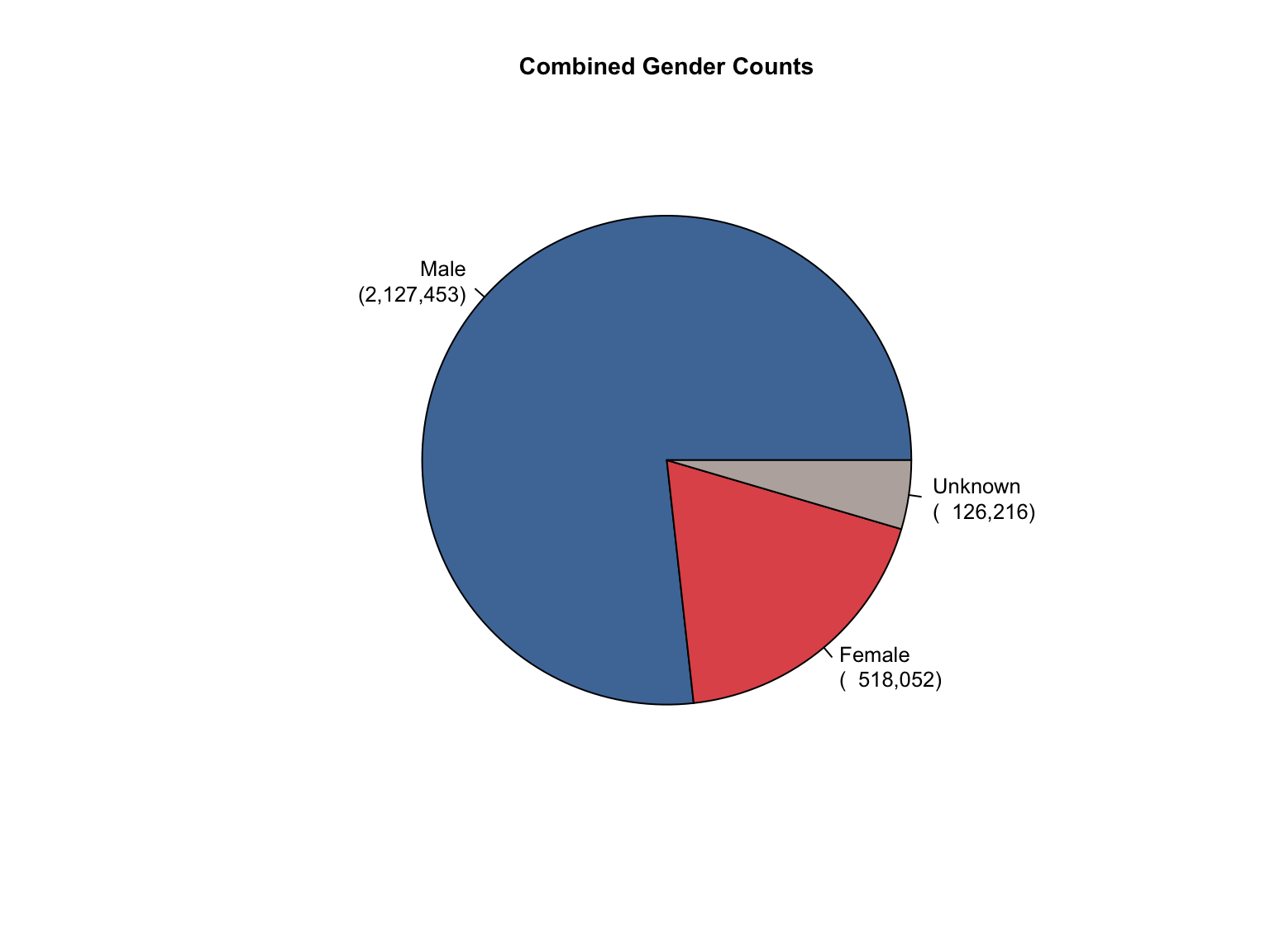
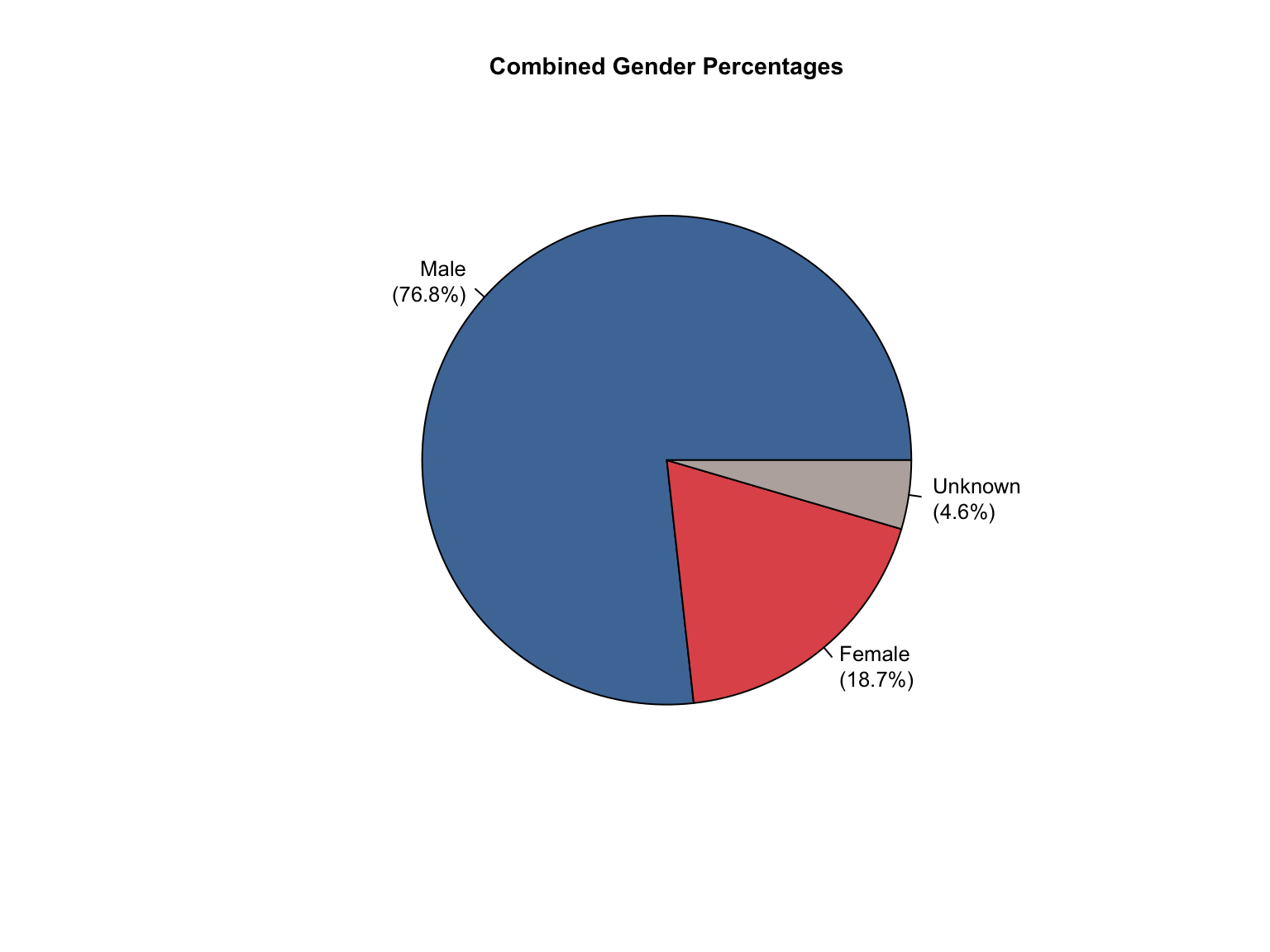
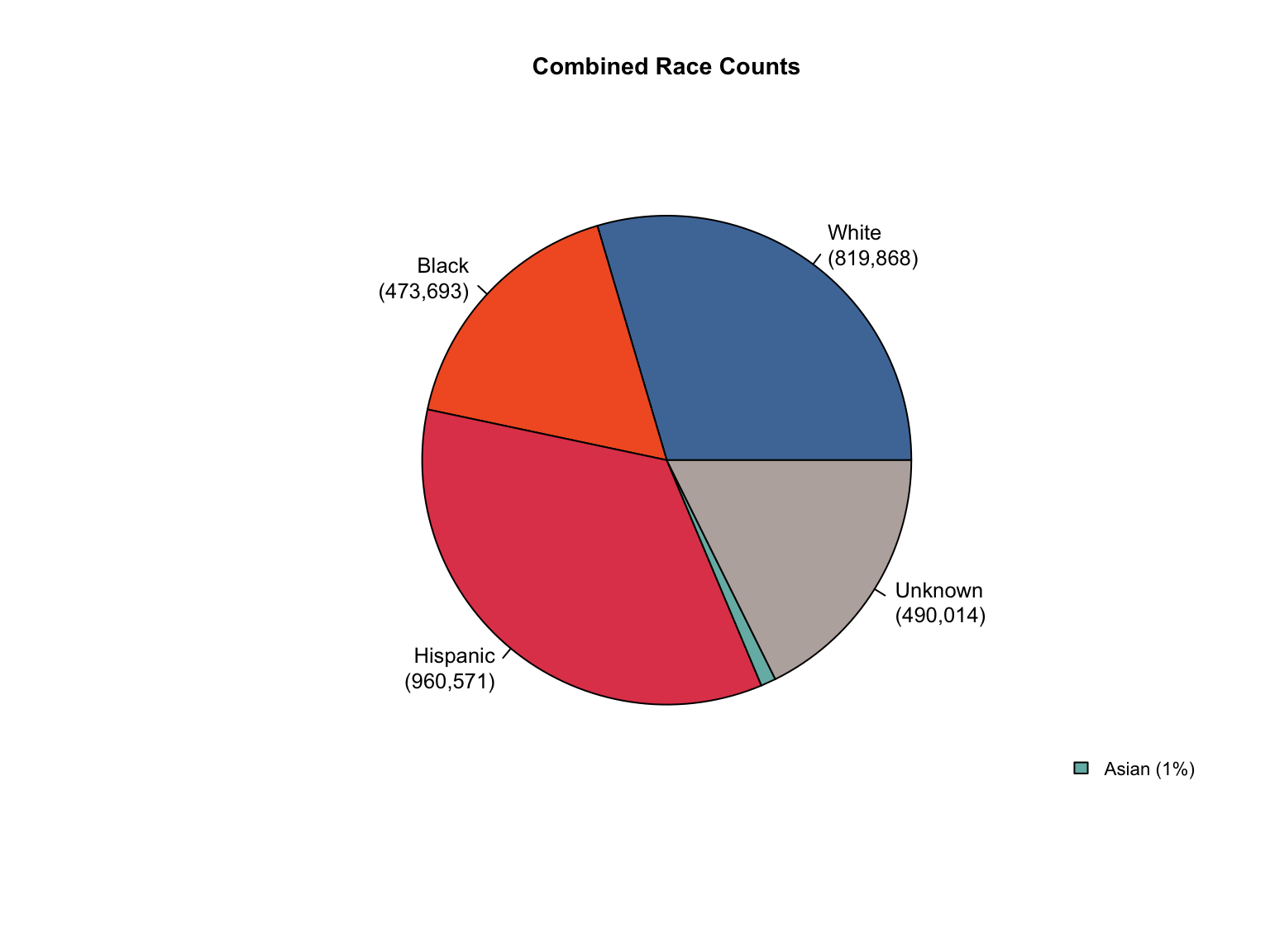
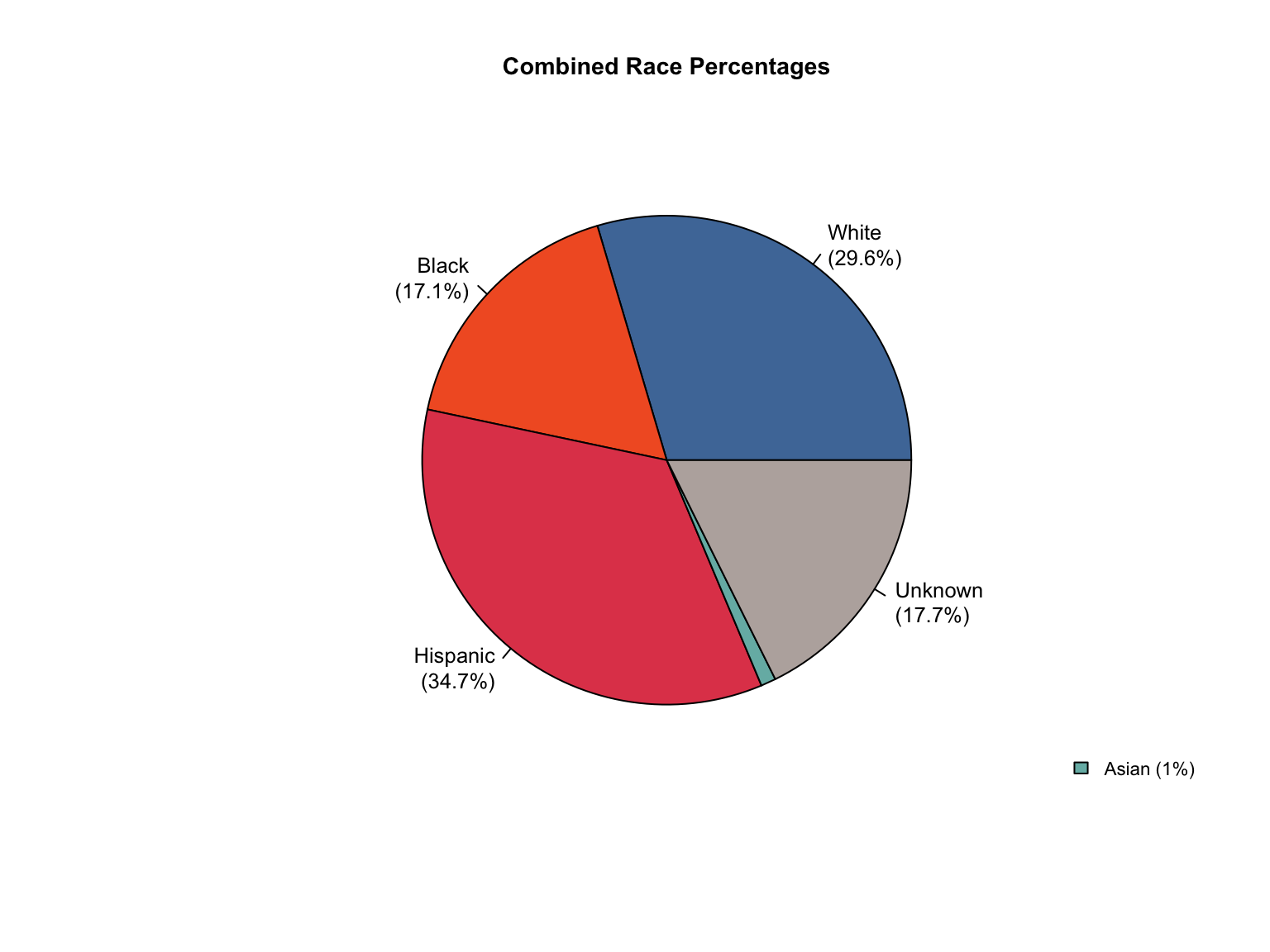
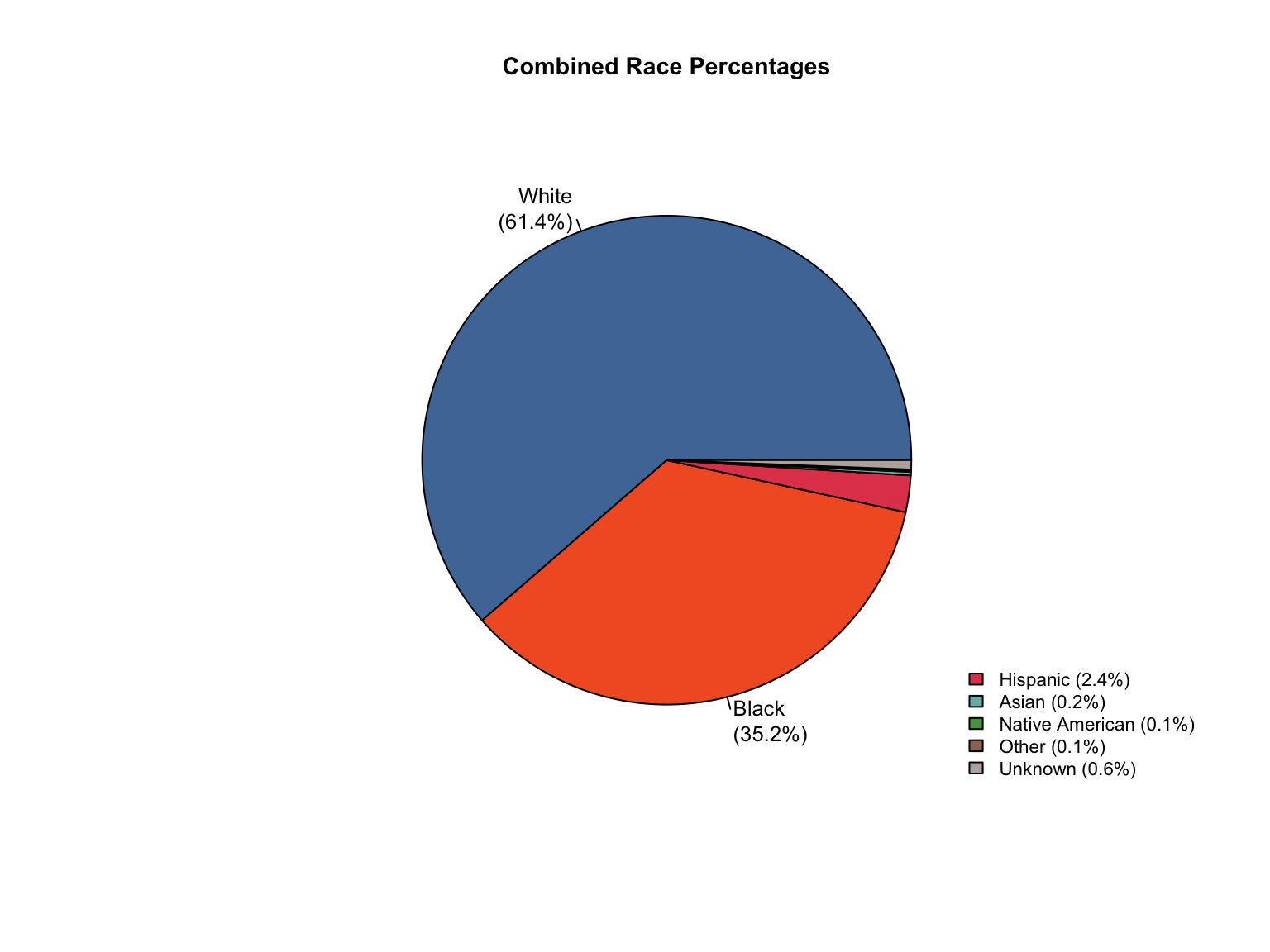
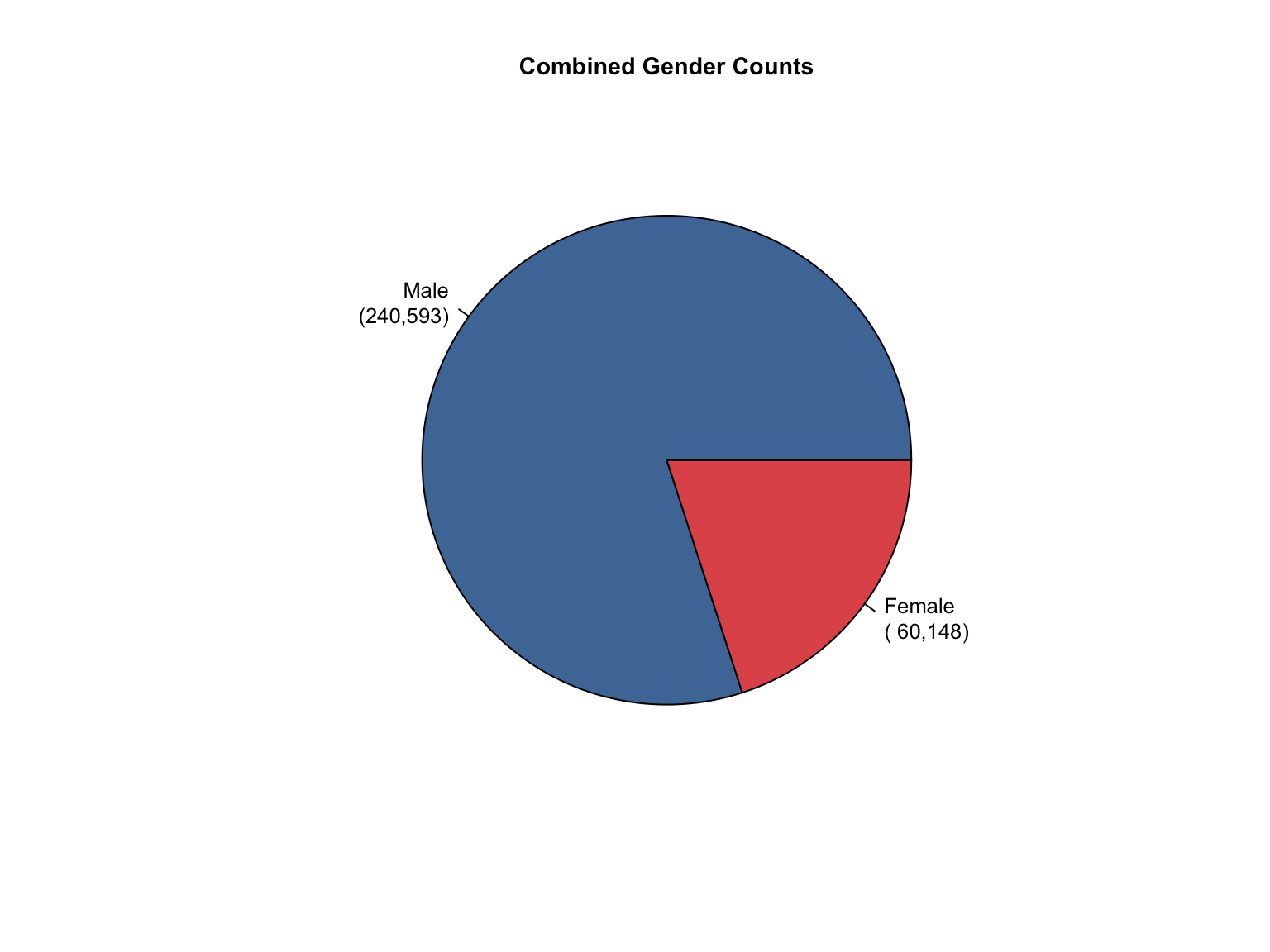
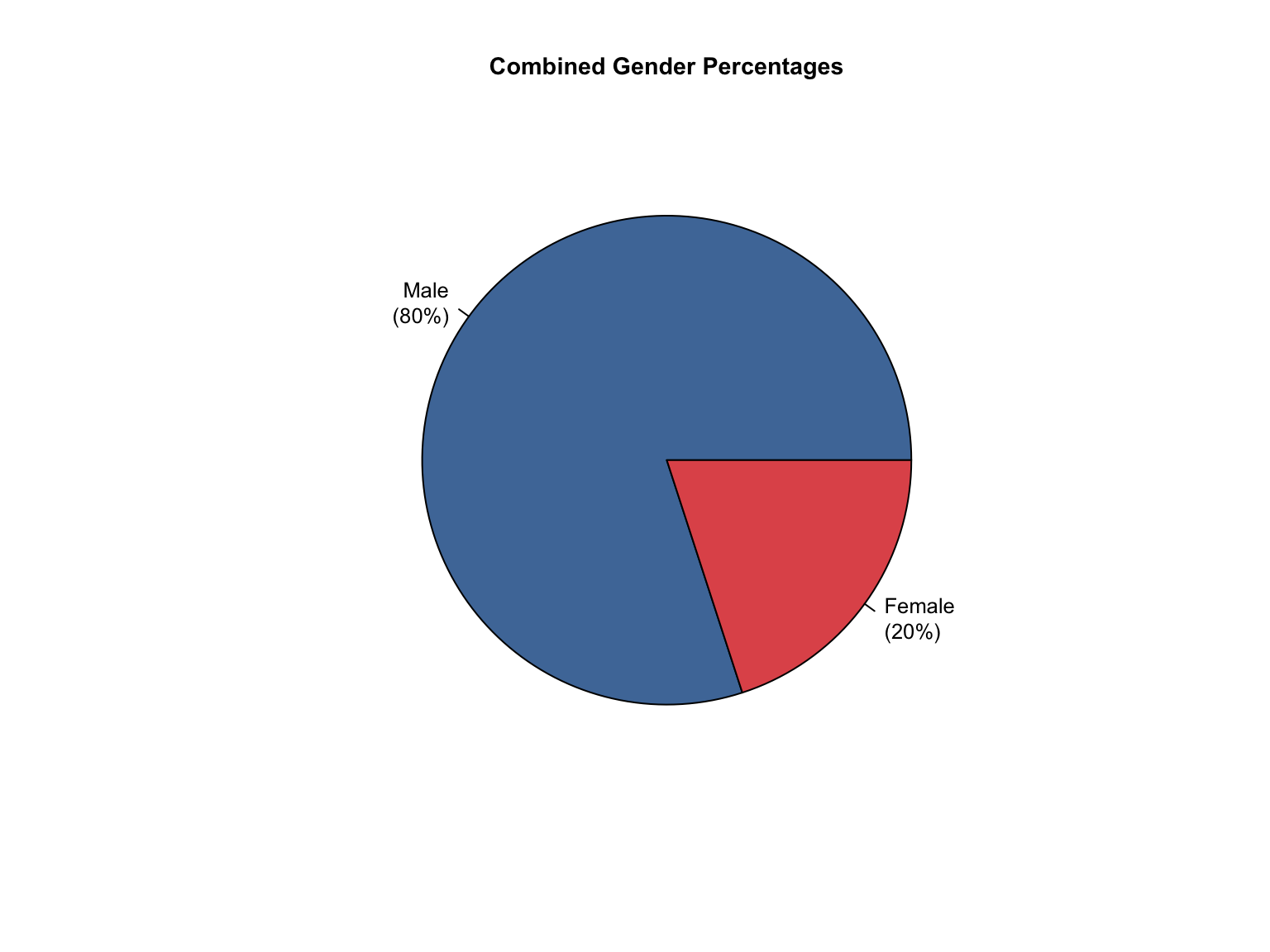
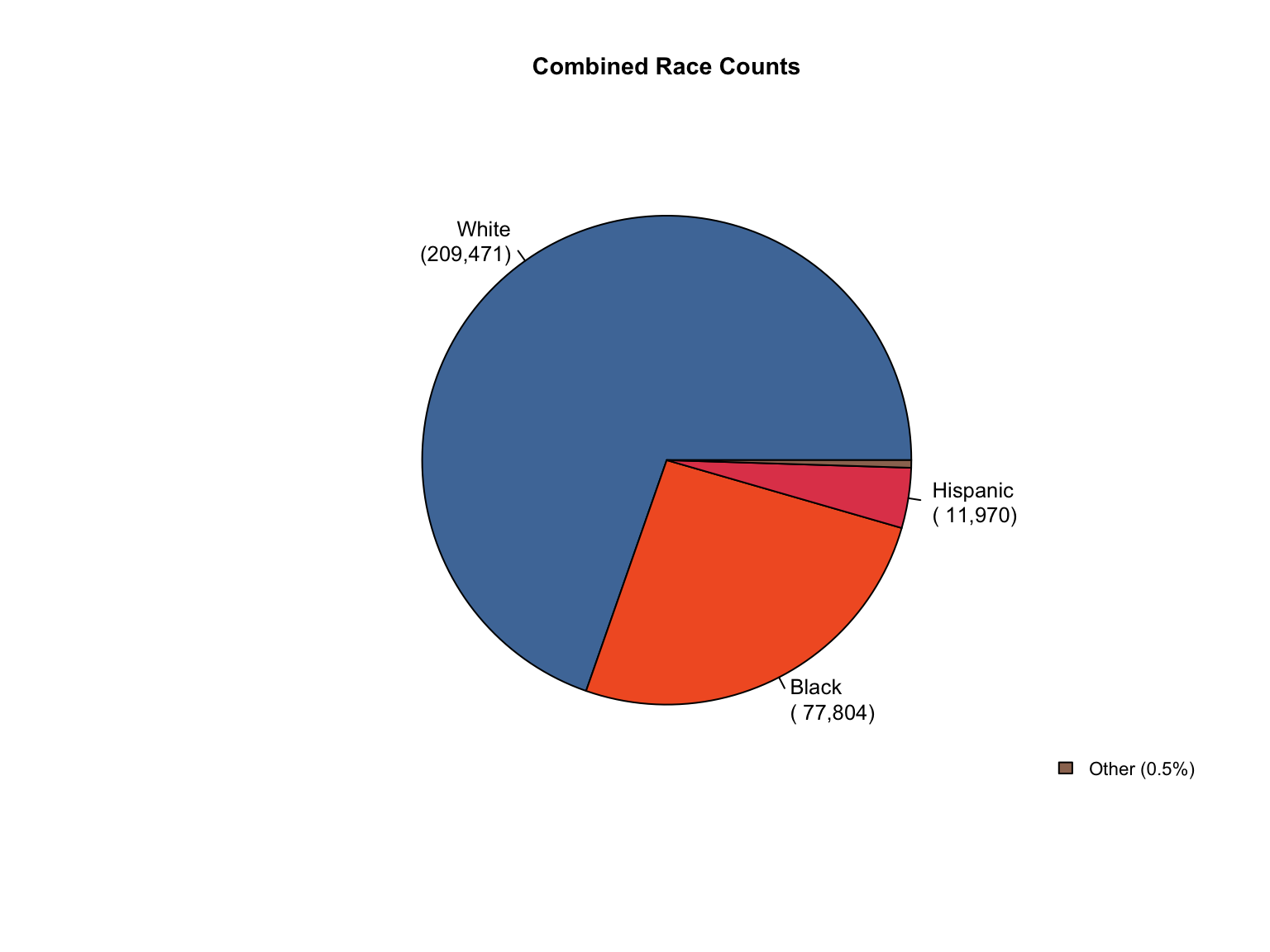
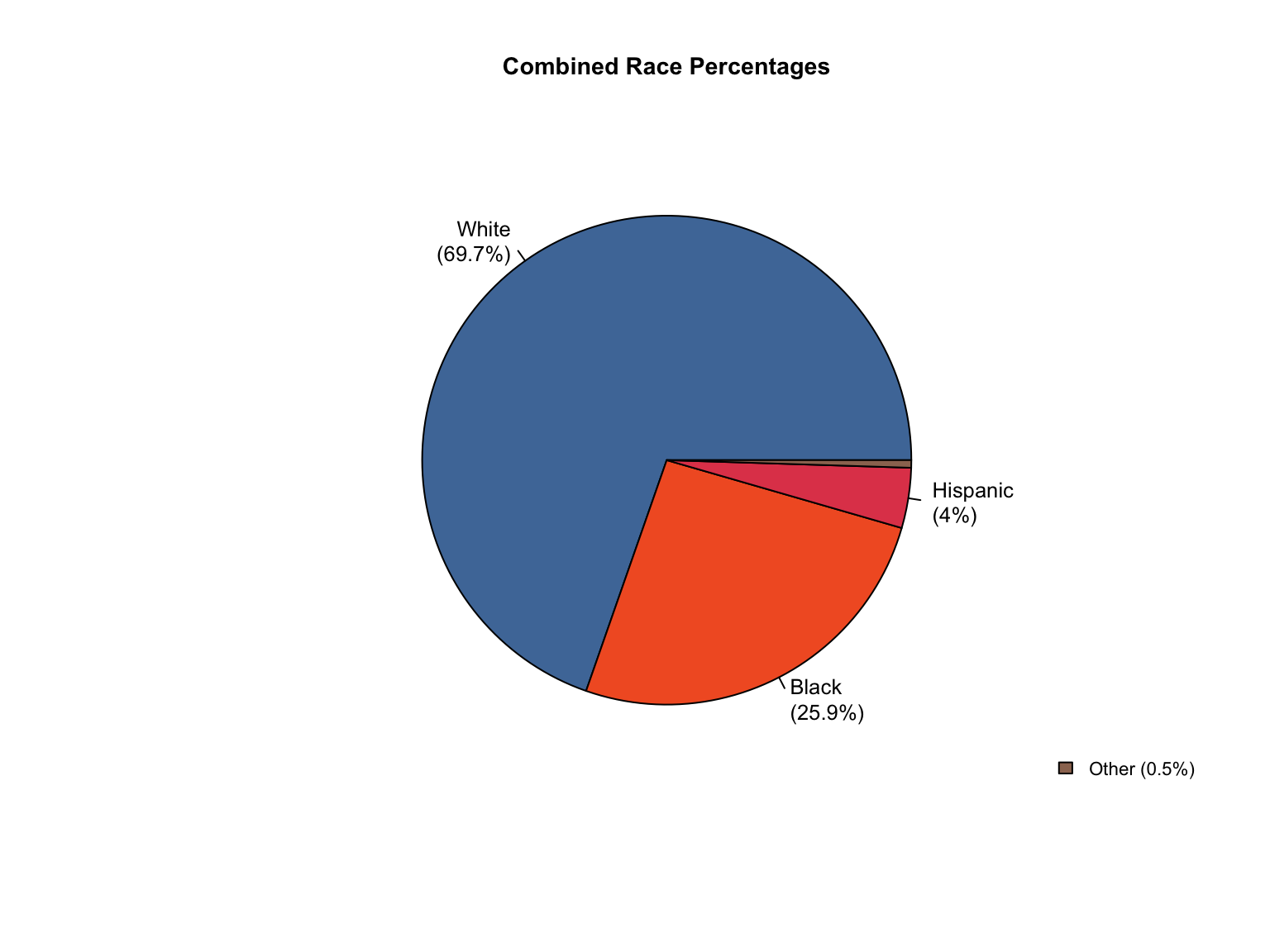
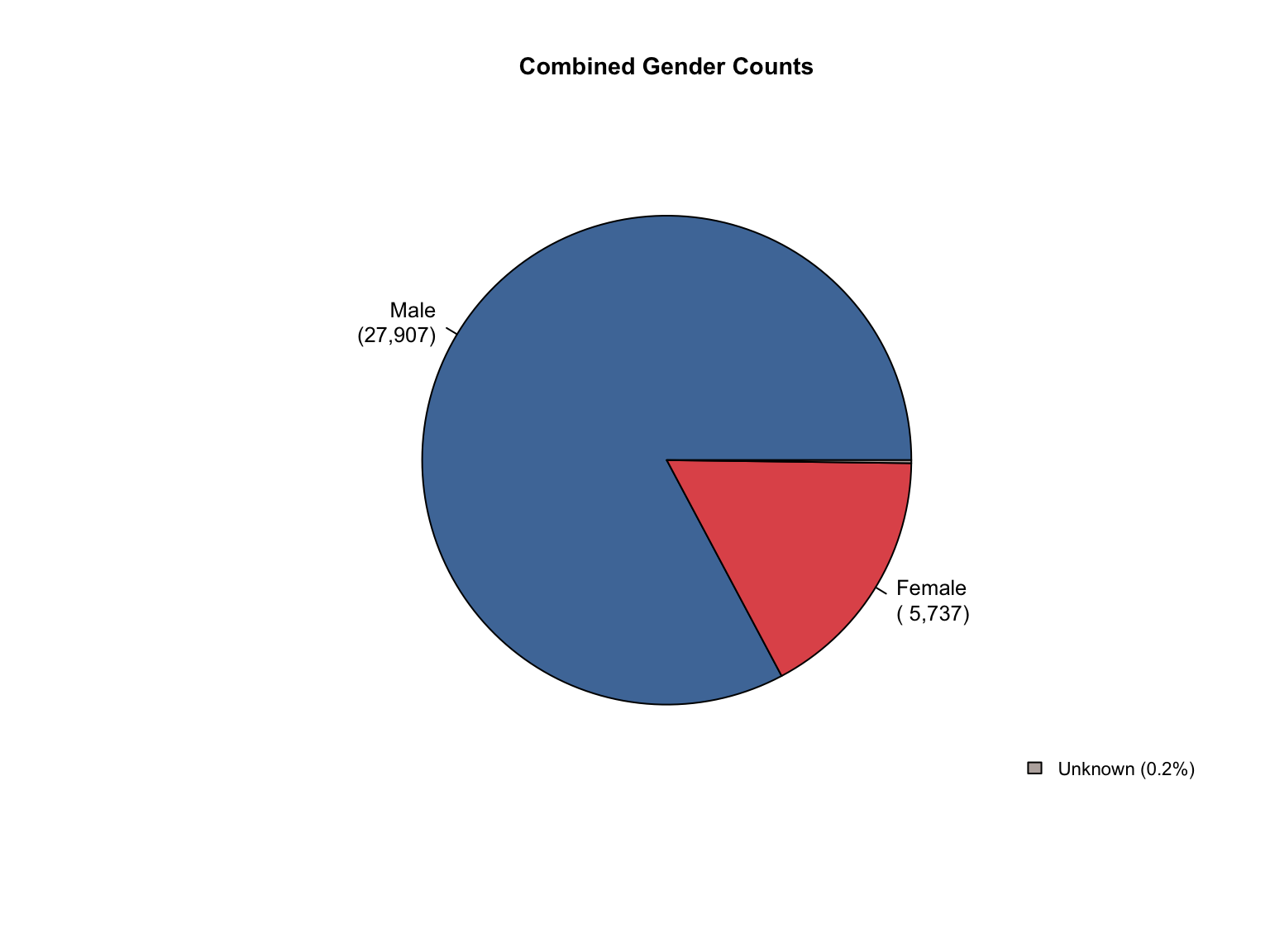
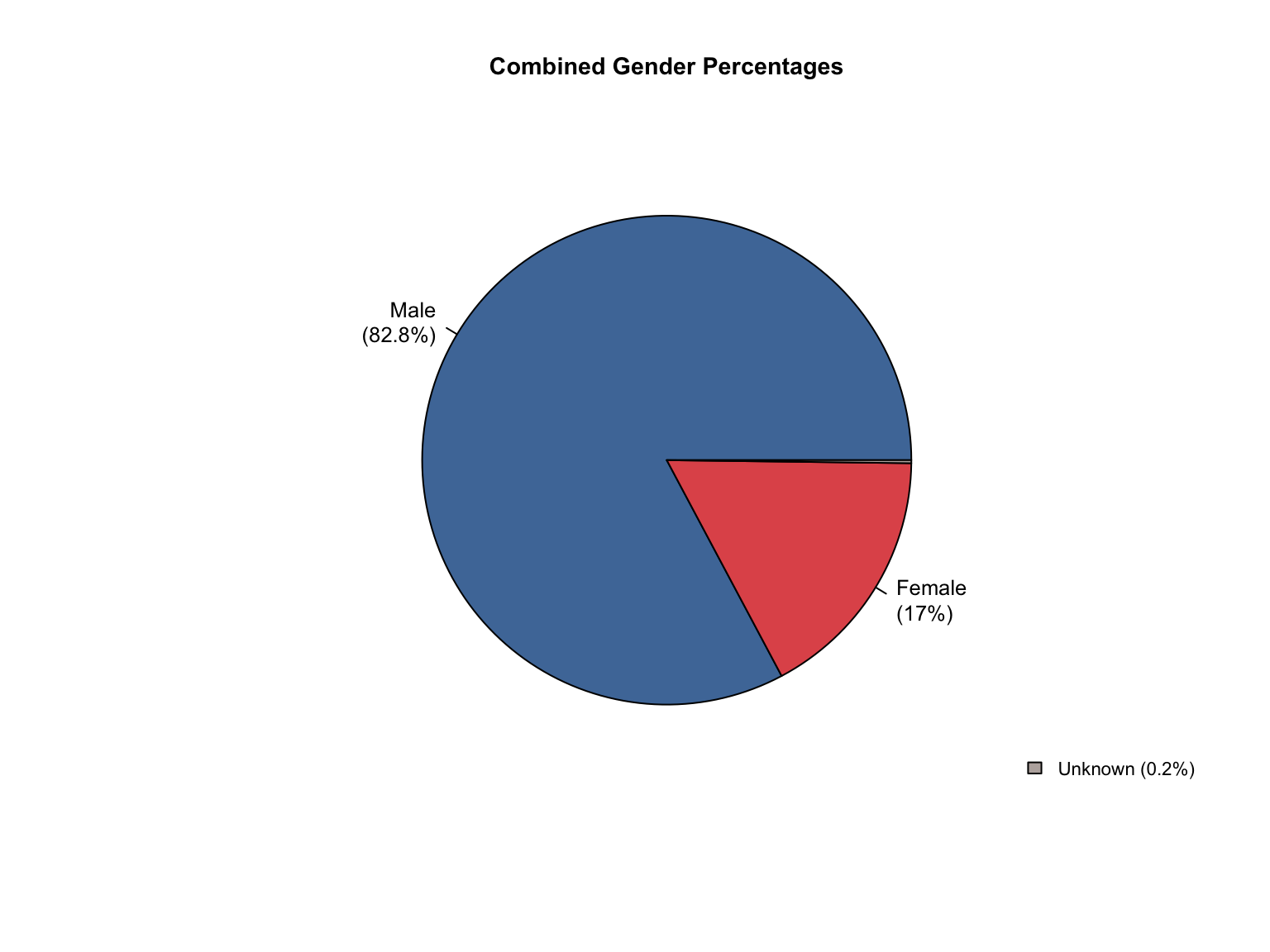
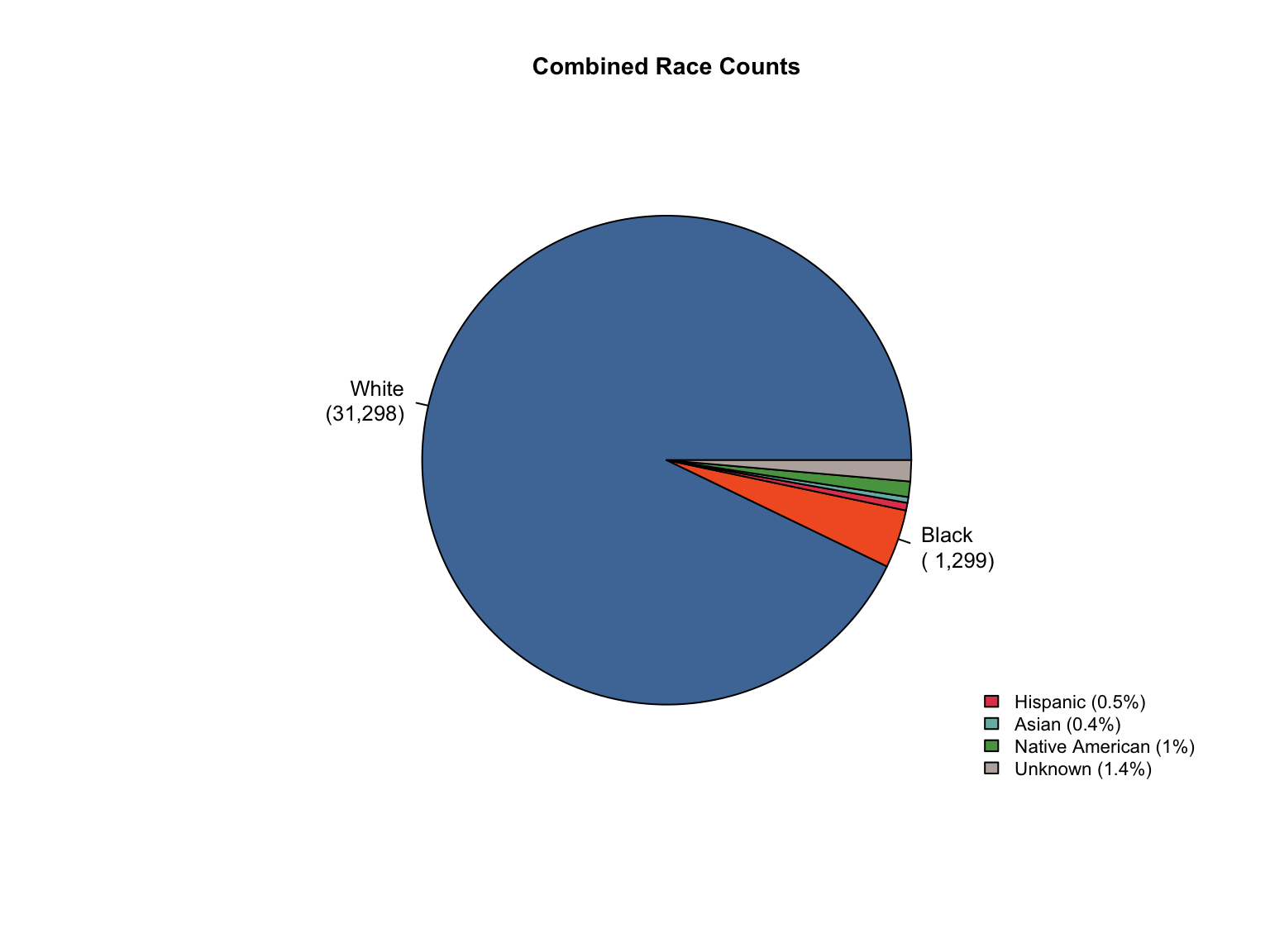
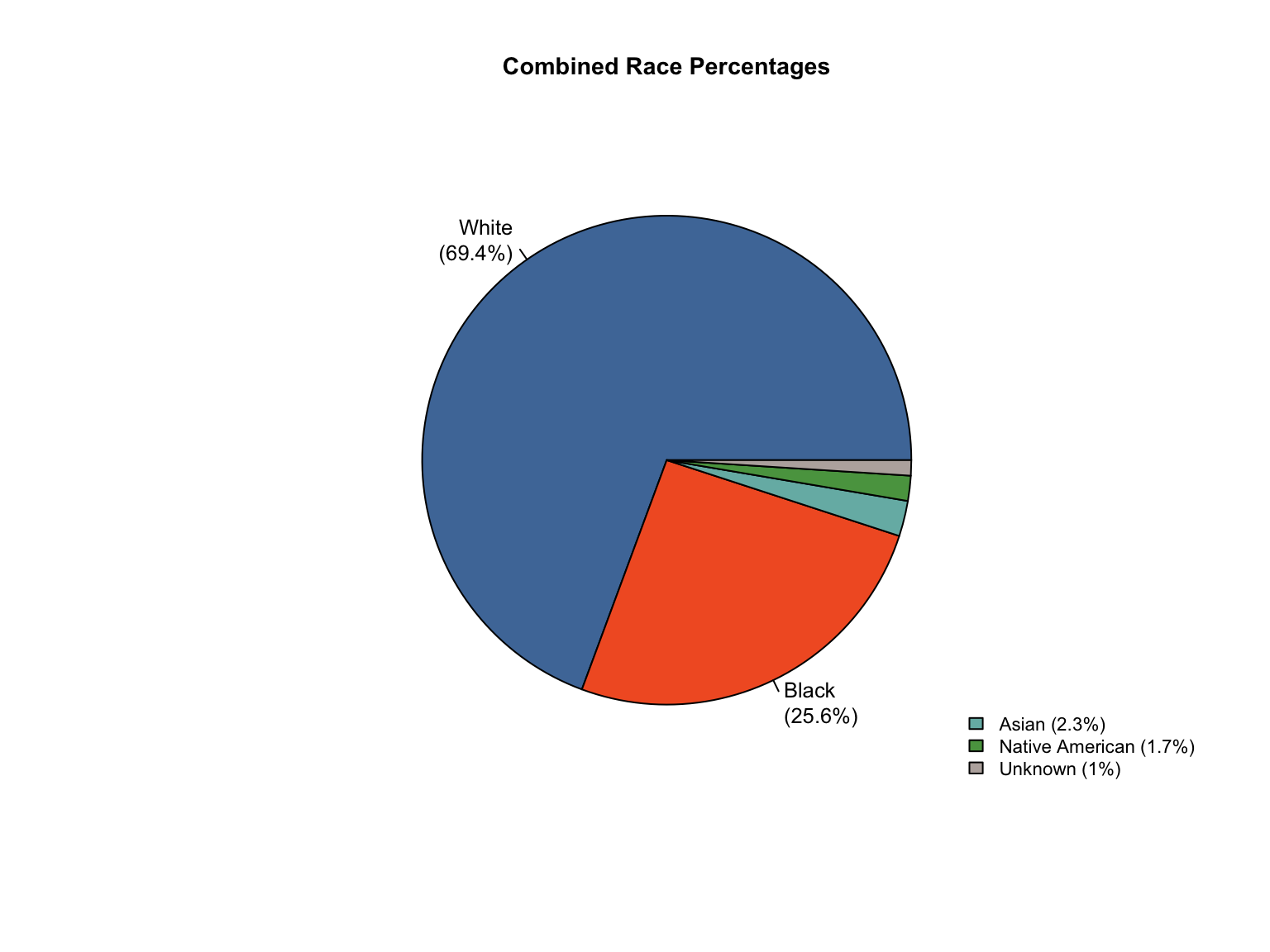
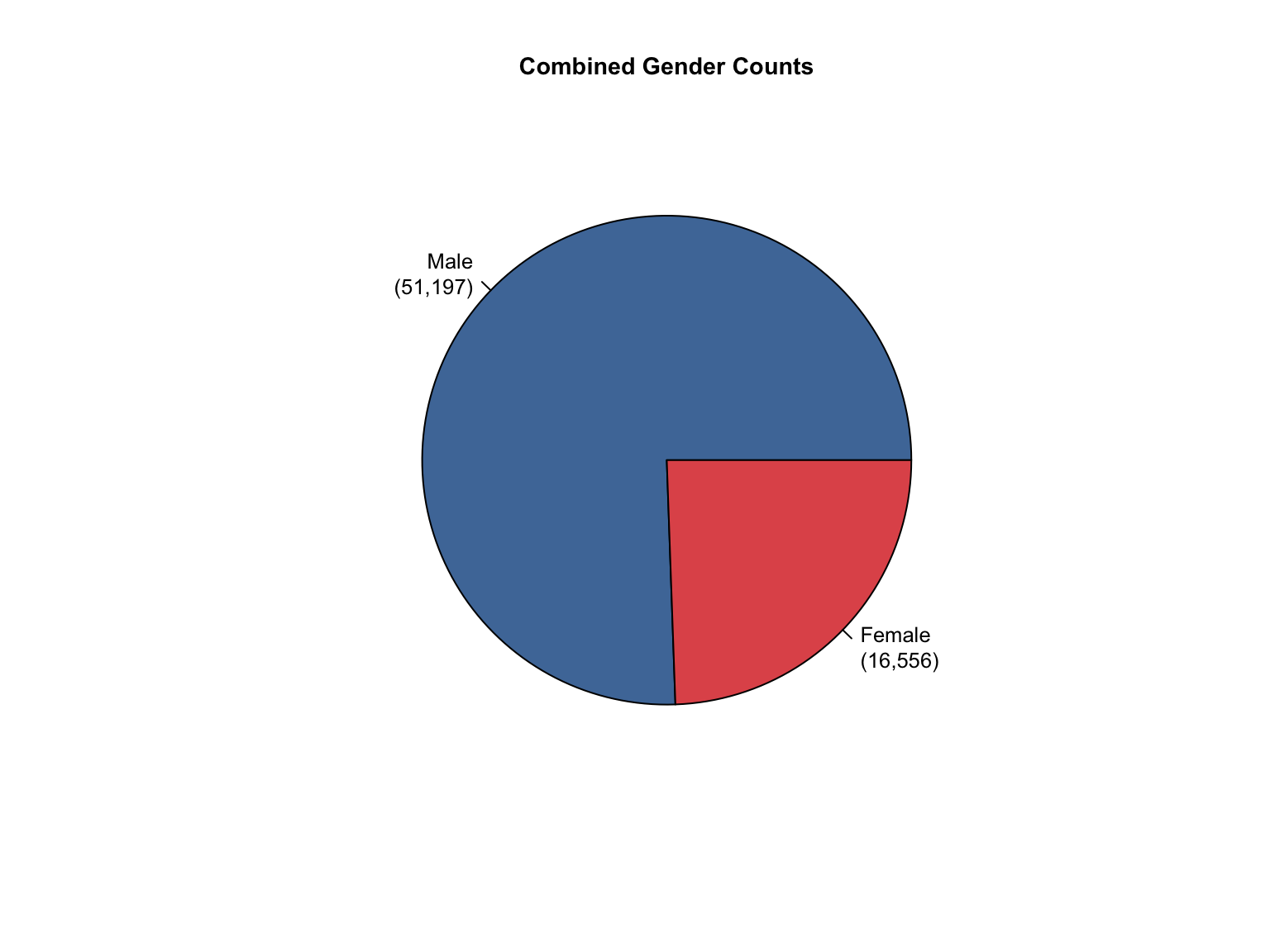
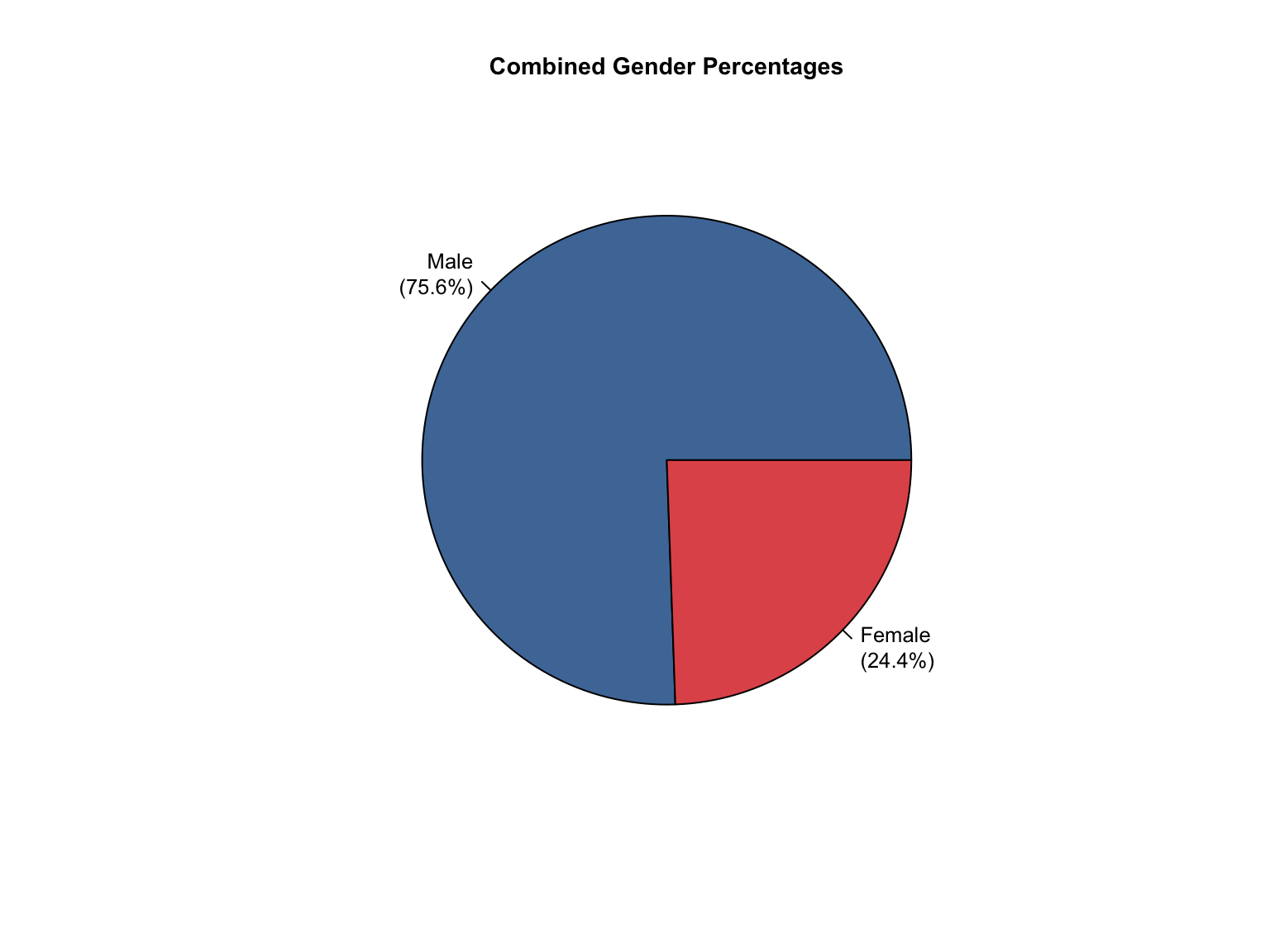
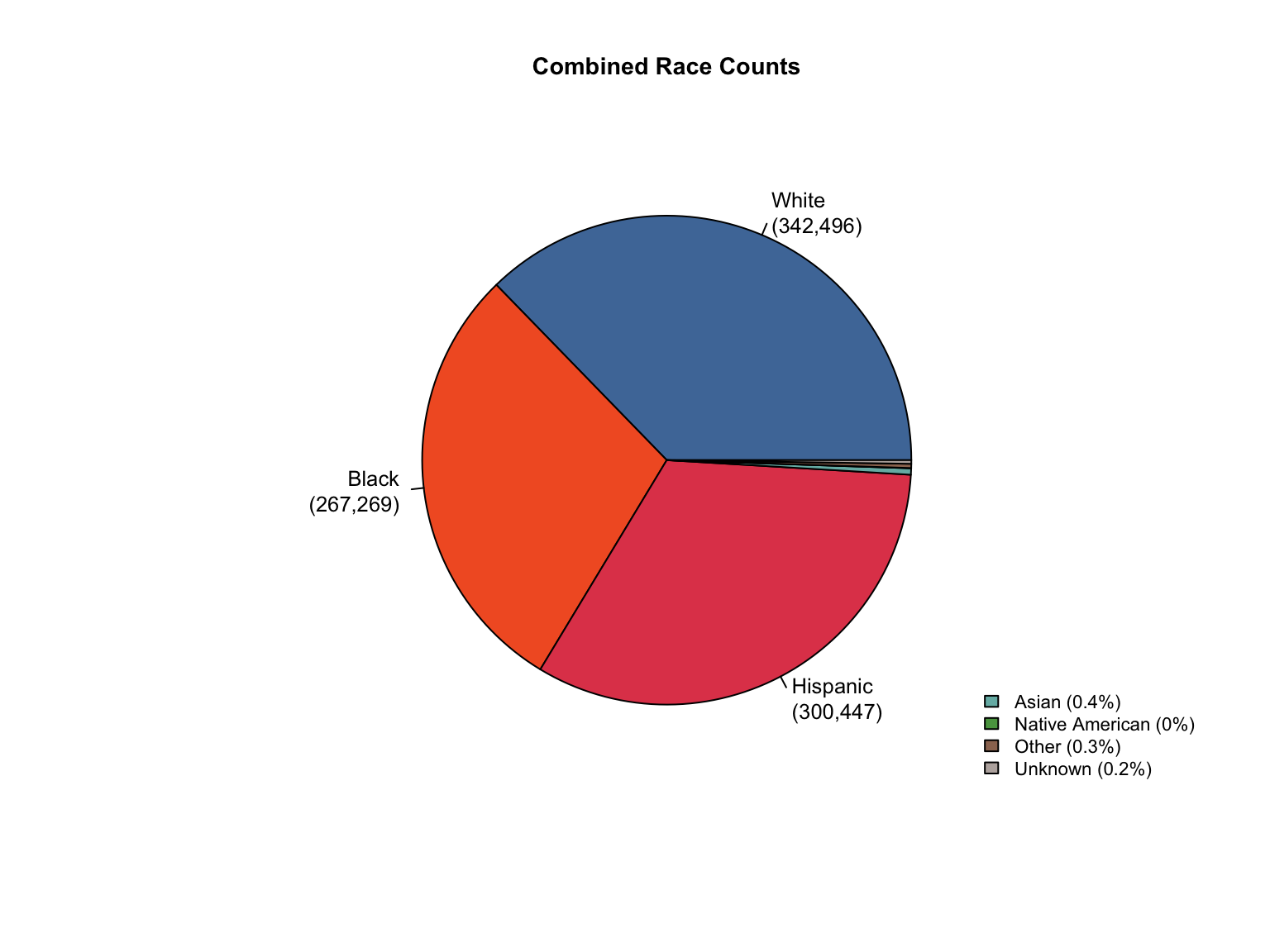
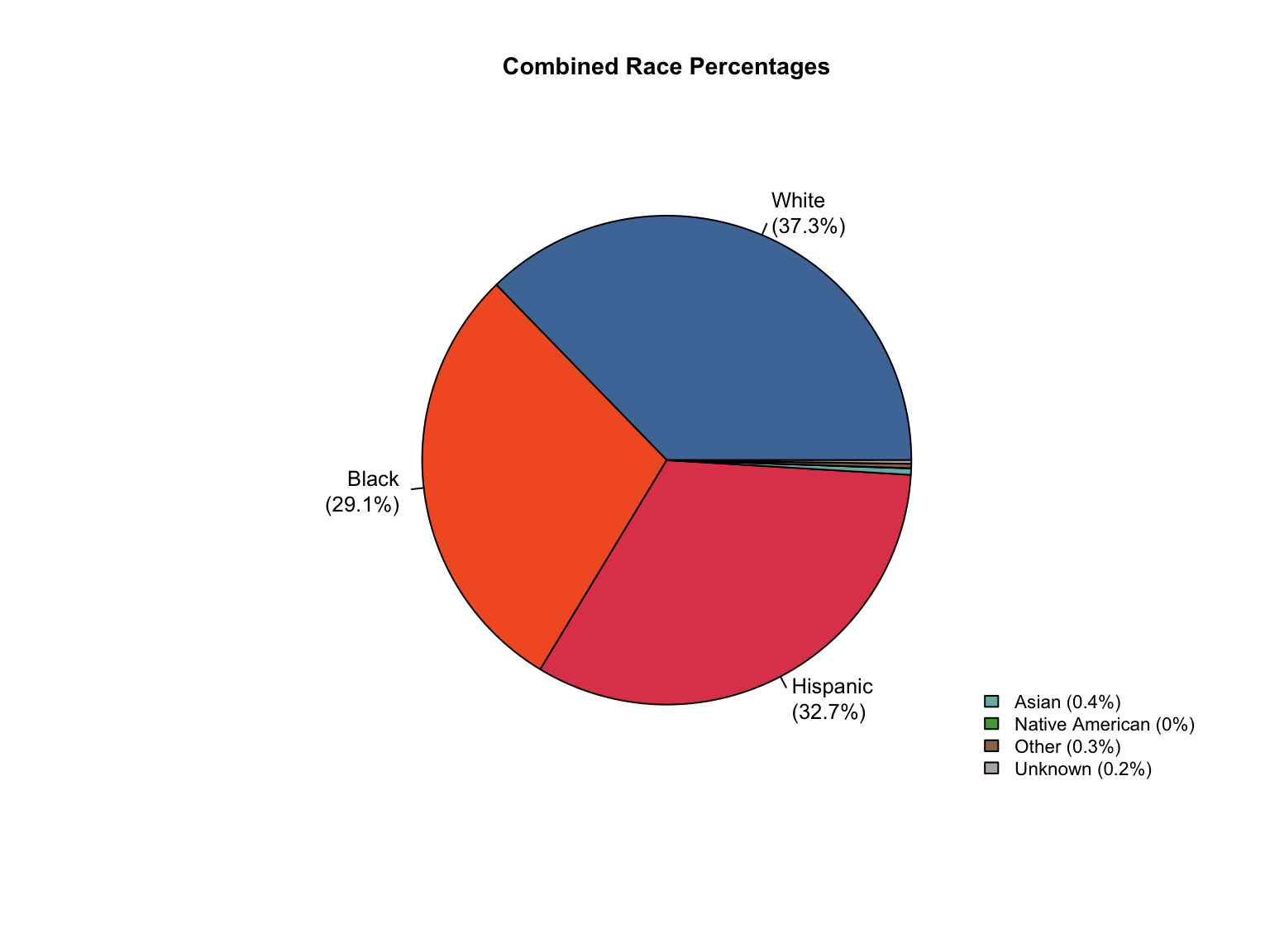
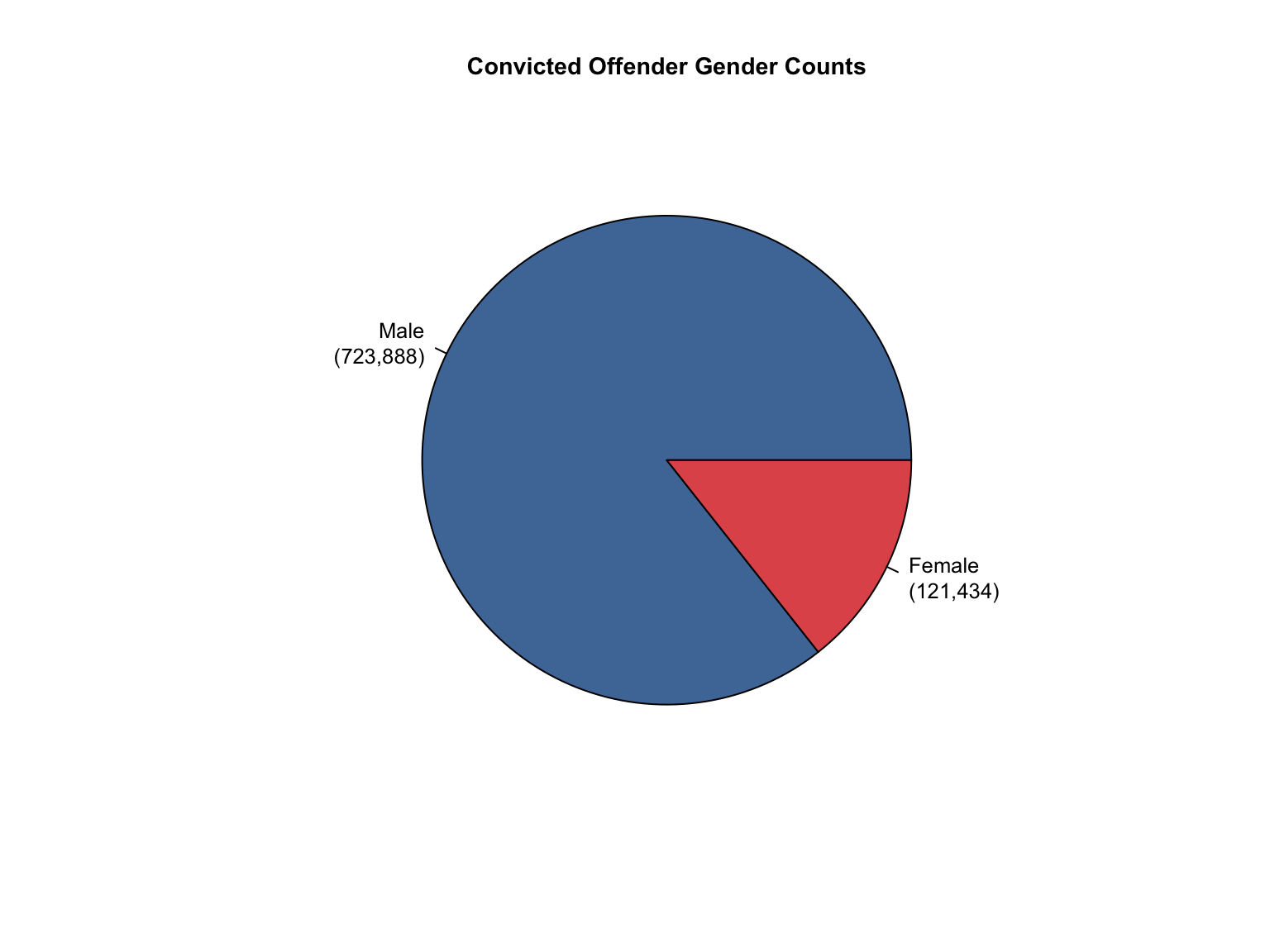
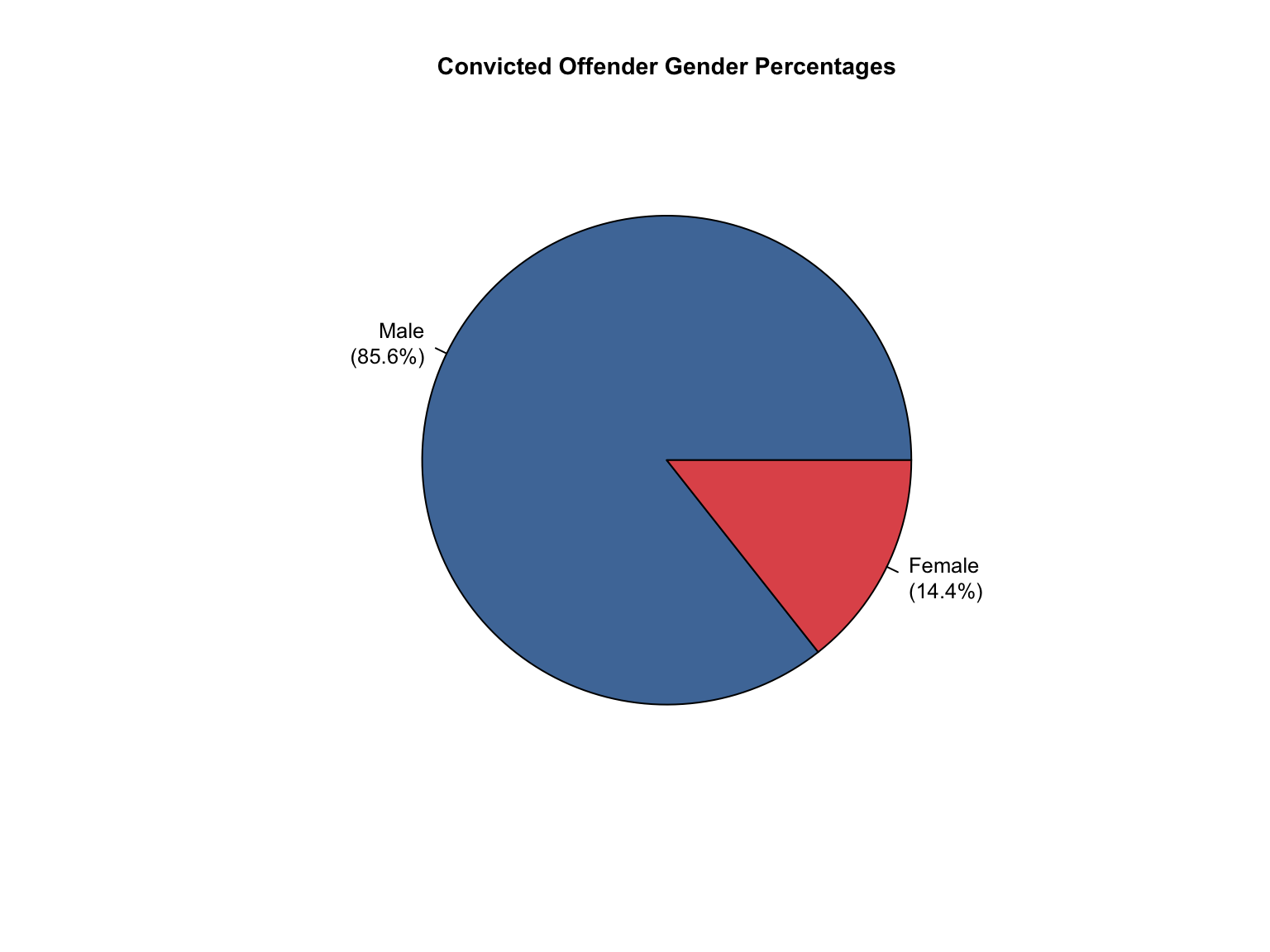
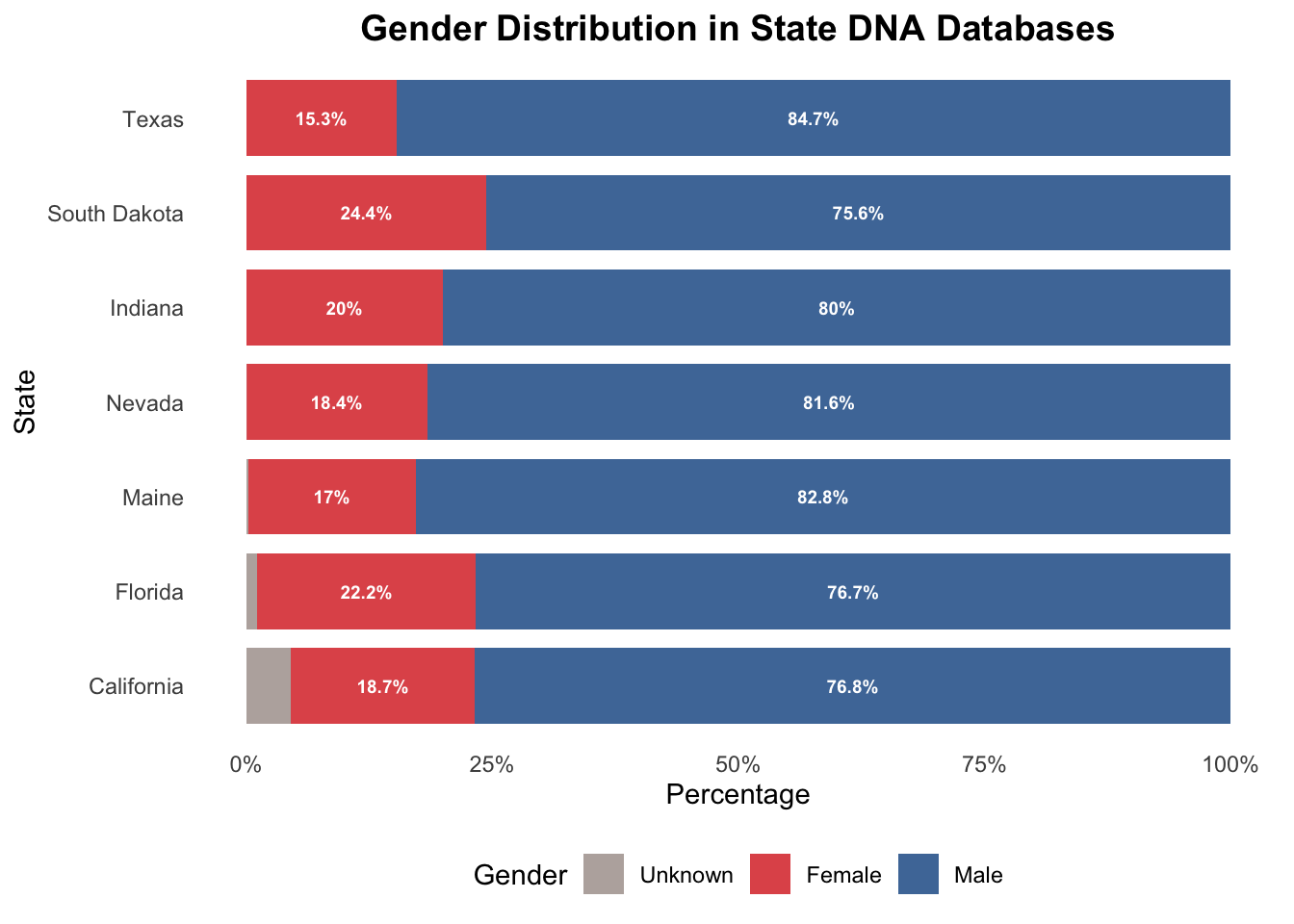
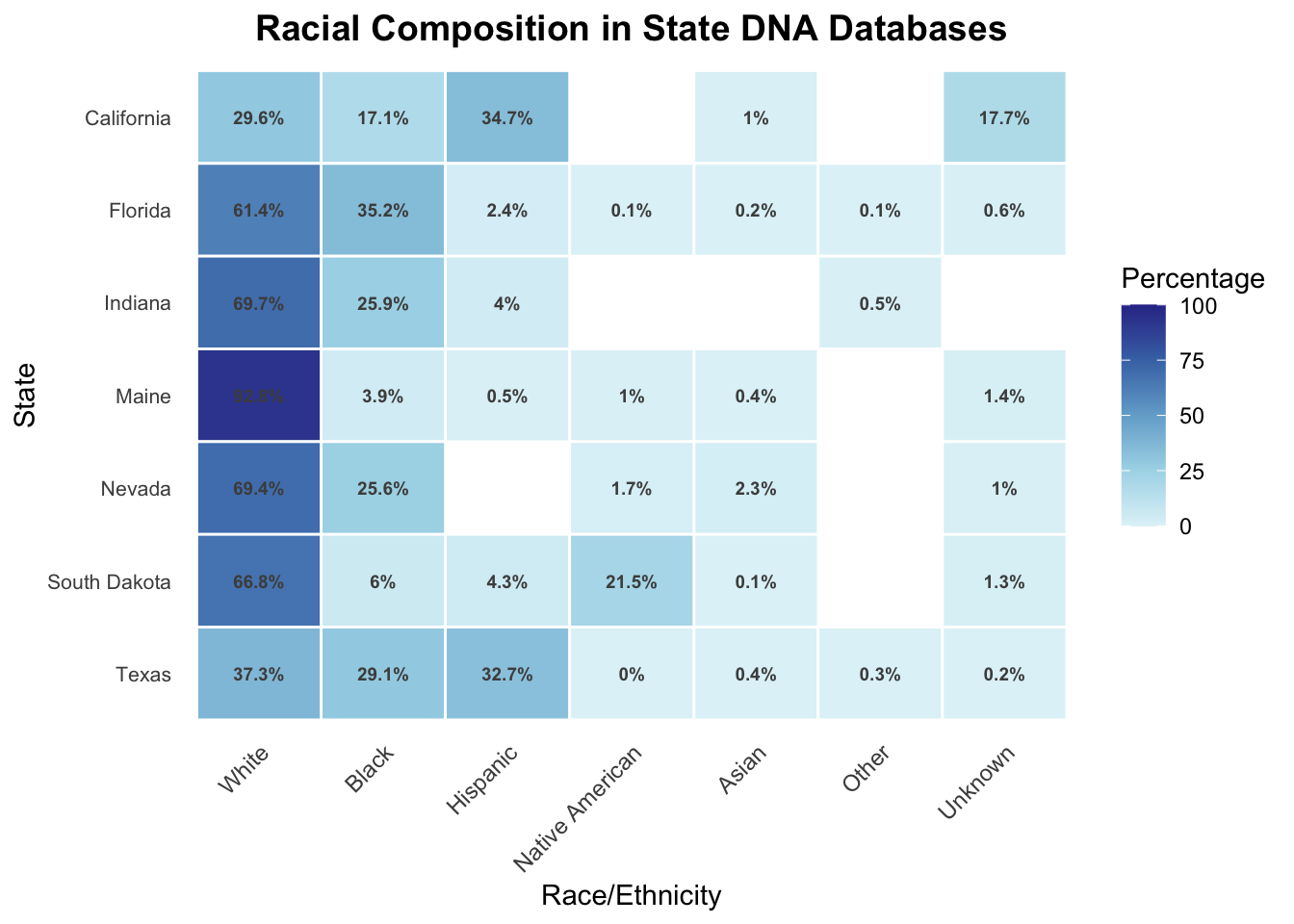
3.8 Combined Dataset
3.9 Metadata table
4 Saving Processed Data
Show final saving process code
# Define output pathsoutput_dir <-here("data", "foia", "final")dir.create(output_dir, recursive =TRUE, showWarnings =FALSE)# Save the combined datasetfoia_output_path <-here(output_dir, "foia_data_clean.csv")write_csv(foia_combined, foia_output_path)cat(paste("✓ Saved combined FOIA data to:", foia_output_path, "\n"))# Save the metadatametadata_dir <-here("data", "foia", "intermediate")metadata_output_path <-here(metadata_dir, "foia_state_metadata.csv")write_csv(foia_state_metadata, metadata_output_path)cat(paste("✓ Saved state metadata to:", metadata_output_path, "\n"))# No additional copies are written to shared version folders here; use# analysis/version_freeze.qmd when a full processed-data release is needed.cat("\n✅ All processing complete! Final files written to data/foia/.\n")
✓ Saved combined FOIA data to: /Users/tlasisi/GitHub/PODFRIDGE-Databases/data/foia/final/foia_data_clean.csv
✓ Saved state metadata to: /Users/tlasisi/GitHub/PODFRIDGE-Databases/data/foia/intermediate/foia_state_metadata.csv
✅ All processing complete! Final files written to data/foia/.
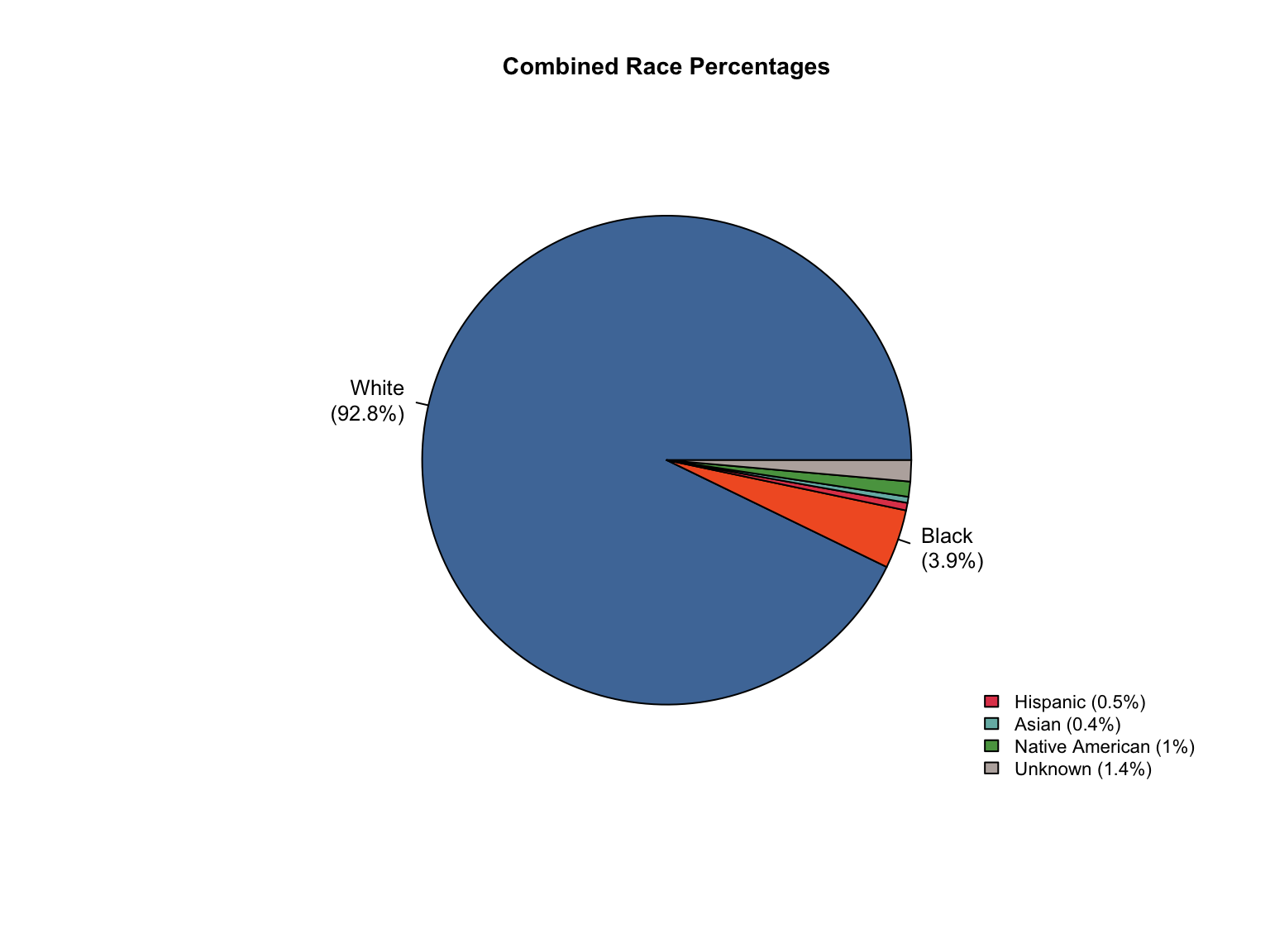
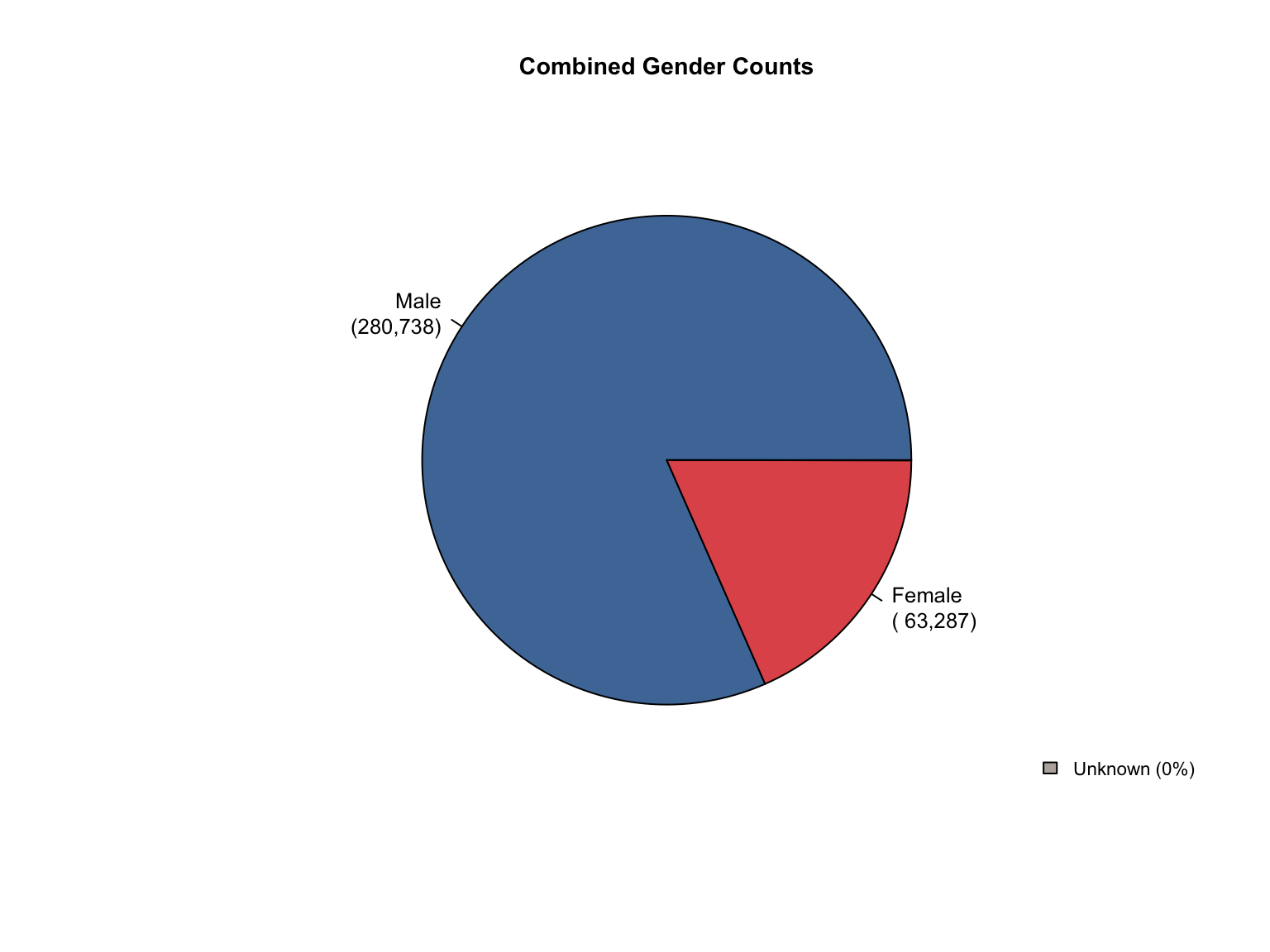
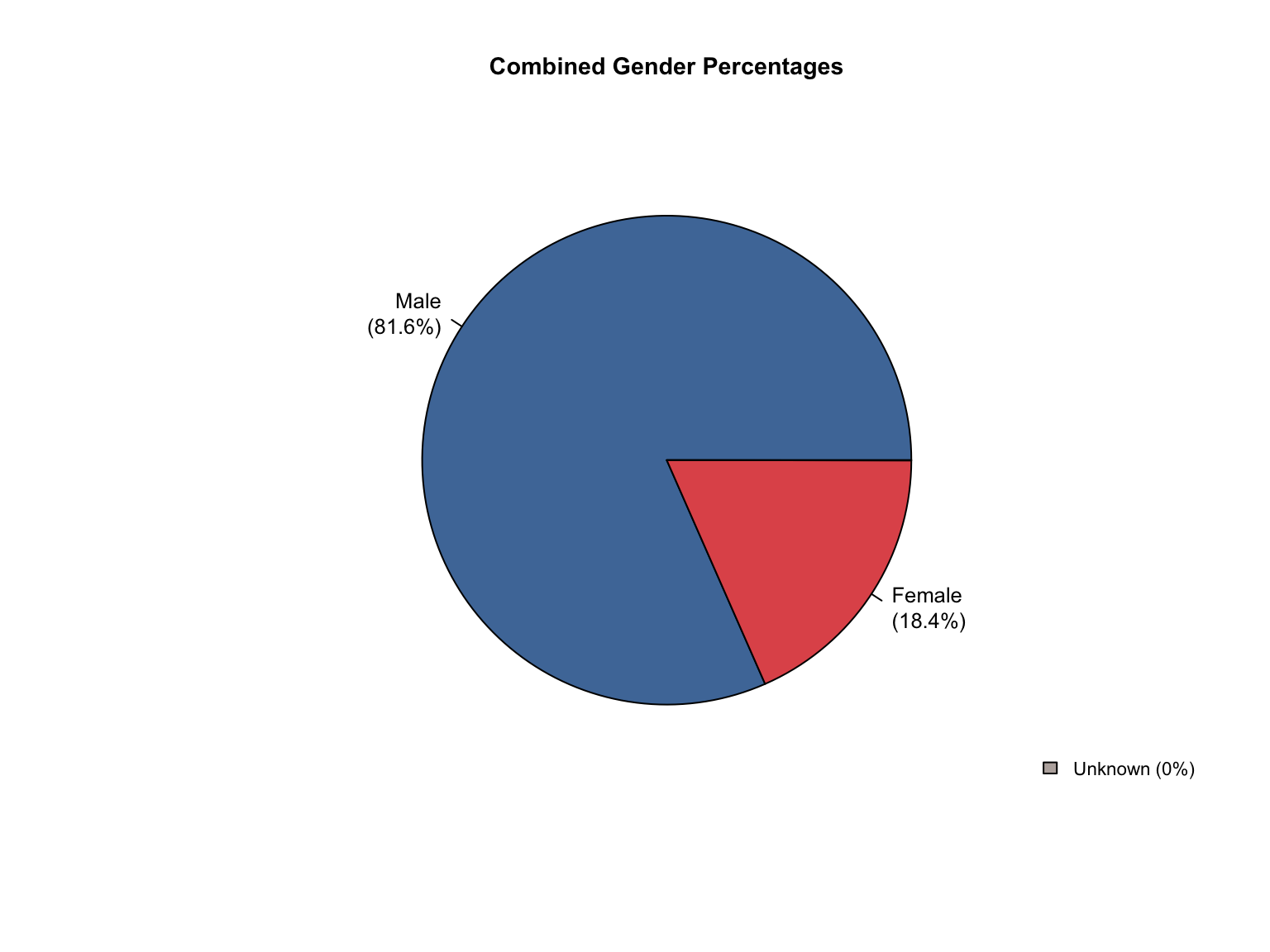
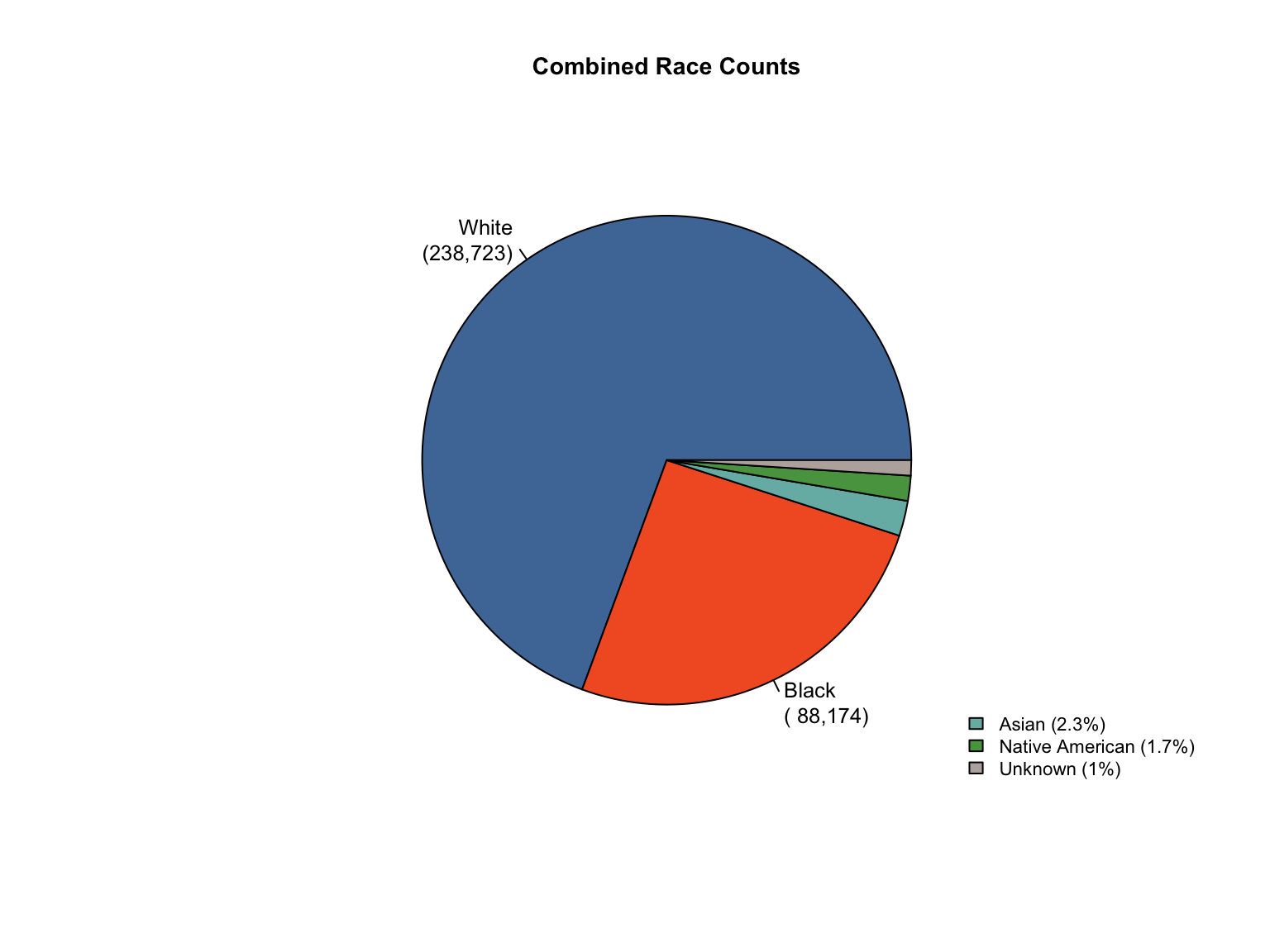
5 Conclusions
Data Acquisition and Harmonization: We ingested seven unique state datasets (california_foia_data.csv through texas_foia_data.csv), each with distinct reporting formats, terminology, and levels of completeness. Through a systematic processing workflow, we harmonized these into a single, tidy long-format dataset (foia_combined), ensuring consistency across all variables.
Standardization of Terminology: A significant challenge was the non-standard terminology used across states. We implemented a rigorous process to map all state-specific terms to a common data model:
Offender Types: Standardized to "Convicted Offender", "Arrestee", and "Combined".
Race Categories: Mapped terms like "Caucasian", "African American", and "American Indian" to standardized categories ("White", "Black", "Native American").
Total Profiles: Consolidated terms like "total_flags" to "total_profiles".
Imputation and Calculation of Missing Data: To ensure comparability, we calculated values that were not directly provided by the states:
Derived Percentages: For states providing only counts (CA, TX), we calculated percentage compositions.
Derived Counts: For states providing only percentages (IN), we calculated absolute numbers using reported totals.
Calculated Totals: We created "Combined" offender type totals for states that only reported separate "Convicted Offender" and "Arrestee" figures.
Inferred Categories: We added "Unknown" race and "Male" gender categories where they were logically missing but necessary to reconcile reported totals (CA, TX).
Quality Assurance and Transparency: A core principle of this project was maintaining transparency and data provenance. This allows future researchers to understand exactly what was provided by the state versus what was derived during processing.